Last week, Idera, Inc. sponsored Enterprise Data World 2018 in San Diego, CA. As usual, it was a fantastic event, organized by the great team at DATAVERSITY. I had the privilege of presenting 3 sessions and interacting with many attendees throughout the conference. Based on the discussions, it is clear that organizations are continually challenged by very complex data environments. Part of this is due to a proliferation of different technologies and data platforms, but there are additional challenges posed by identifying, ingesting, and utilizing data that the organization itself does not create nor own. This type of data requires significant analysis, scrutiny, and processing before it can be combined with trusted organizational data sources to facilitate informed analytics and decisions.
The difficulty in understanding and managing data resources is compounded further, since the data stores are now likely to be a collection of cloud and on-premise deployments, with widely varying levels of data quality.
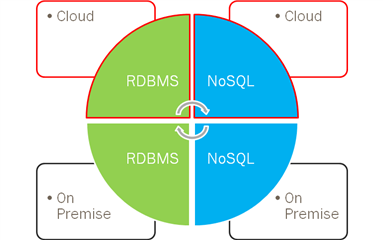
Thus, we are typically dealing with varying combinations of:
- Data origin: internal vs. external environment
- Data store type: relational database (RDBMS) vs. NoSQL
- Deployment: on premise vs. cloud
Traditional descriptions do not adequately describe the complexity introduced by the combination of all these factors. Therefore, I have decide to coin a new phrase, referring to it as the "Multi-Hybrid Data Ecosystem."
In discussion, it is common to refer to "the data warehouse" or the "data lake" which can leave the impression that there is only one. However, in our complex ecosystem, we will typically have a myriad of raw data stores, document stores, OLTP relational databases, operational data stores and data warehouses. Likewise, the data lake is not one physical data store. Rather, it is a concept which is more commonly being referred to as the Logical Data Lake.
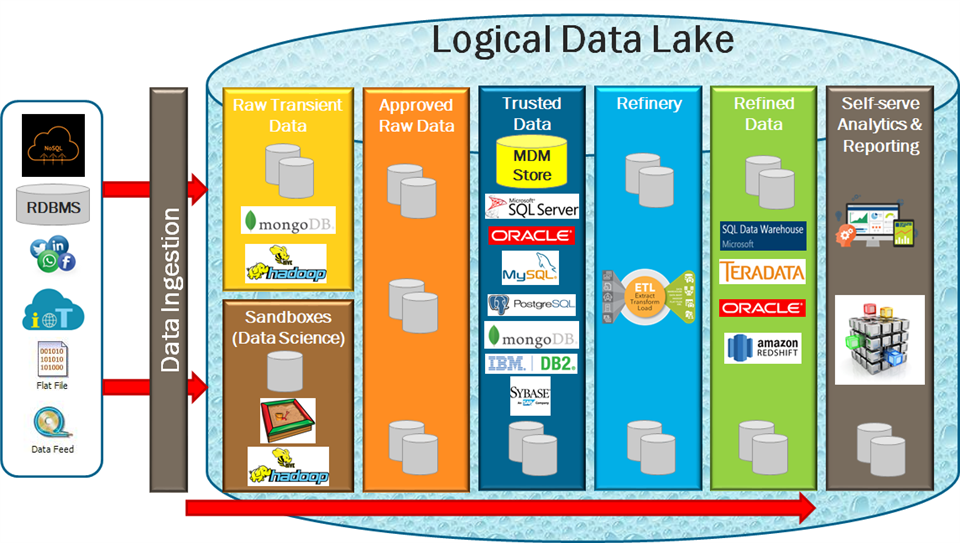
Following the flow of the diagram from left to right, the logical data lake begins once data is ingested, from storage of raw transient data, raw data analysis (data science), approved data stores, trusted data stores, the information refinery (including ETL), refined data (including data warehouse) which ultimately drives Analytics and Reporting. I have indicated a small subset of the typical data store technologies that could be used in specific areas to provide additional context. There are many more available data store technologies. In addition, the depiction of a specific technology in a given area does not mean that the technology is limited to use in only that area. Several data store platforms have been used in multiple or all areas.
In the past, we have often referred to organizations as information factories. This is more relevant today, than ever before. We can't simply trust the quality of data that we find in a particular data store, particularly if it is a raw data feed that has been ingested from outside sources, such as social media sites. IOT sensor data, 3rd party sites, and other external sources. Continuing with the manufacturing analogy, those raw materials need to be inspected and processed before they can be incorporated into any downstream manufacturing processes. Once approved, that data can be be refined and combined with our trusted data sources.
Data modeling is more important now than ever before. ER/Studio will allow you to map all the relevant data stores in the Multi-Hybrid Data Ecosystem and Logical Data Lake incorporating all sources, targets and data lineage. This will provide an integrated blueprint of physical deployment models, enterprise data dictionaries and enterprise models.
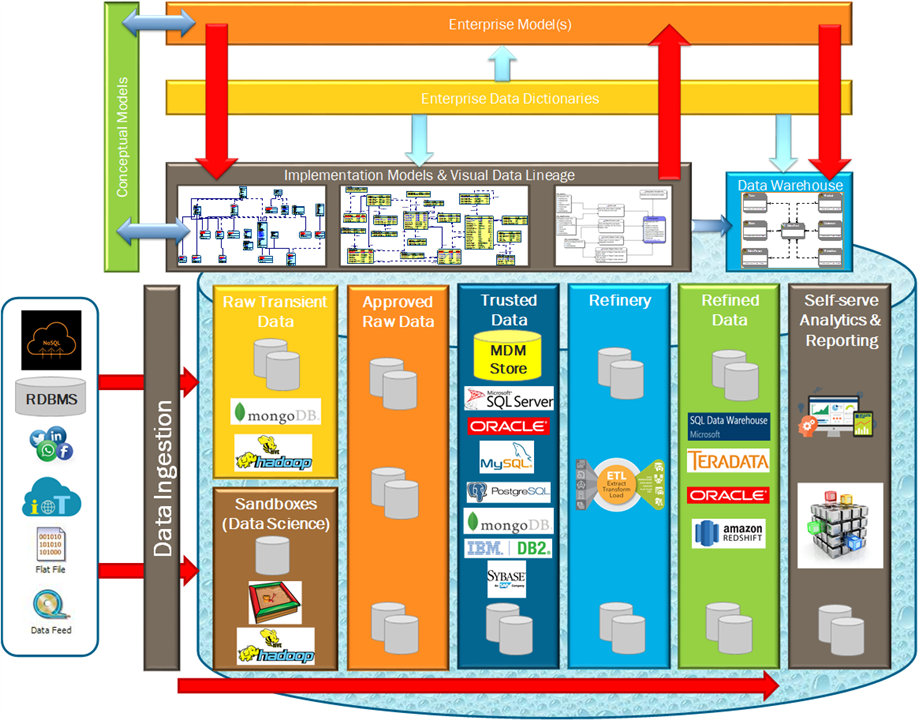
ER/Studio Enterprise Team Edition advances the capabilities further, with an extensive metadata repository, business glossaries, governance and collaboration platform. Request a demo to learn how ER/Studio Enterprise Team Edition can help you conquer the Multi-Hybrid Data Ecosystem.