Building a business glossary is an important facet of modern, data-driven business.
A business glossary is a bank of business terms recorded and defined using business user-friendly language.
Constructing business glossaries, and business glossary management play an important role in an organization’s data governance efforts. They mitigate the potential for miscommunication within and between an organization’s departments by removing ambiguity.
Information recorded within a business glossary helps data stakeholders understand the ontological relationships between data points. This is a vastly important task when managing the complex systems associated with the data-driven era, and should be undertaken comprehensively.
Constructing and maintaining a business glossary ensures stakeholders throughout the organization are on the same page, speaking the same language.
Why You Need to Build a Business Glossary
If you haven’t built a formalized business glossary, the best time to start building one is now.
Consider the term “User”, defined as a current user of a product/service from the “Vendor”.
While the information here is enough to understand the ontological relationship between “User” and “Vendor”, there is still potential for ambiguity.
A software-provider’s definition of “User” might refer to the end-user of their product/service. But what does this mean in a B2B environment? “User” may be used colloquially to refer to the business that has purchased the product/service.
When issuing a product update announcement, the provider of the product/service would need to direct such comms to the “End-user” – i.e. the person(s) who actually uses the product/service.
However, there is enough ambiguity here that a “User” might be misinterpreted as the individual that purchased the product. For large companies with procurement teams, this is unlikely to be the “End-user”.
Misunderstandings like the example above can be hugely impactful to a business – from their reputation to their finances, and a whole host of other risks in between. There is no room for ambiguity when handling sensitive data, for example. An ambiguous business term here could lead to serious legal repercussions including considerable fines.
Building and maintaining a business glossary benefits organizations in a number of ways. Ultimately, business glossaries help organizations standardize and clearly define business terms, mitigating the potential for ambiguity and the risks associated.
7 Steps for Building a Business Glossary
Step 1 – Identify
The first step in governing anything is to decide upon what to govern. Data stewards need to identify the terms that the organization uses. These will come from the common parlance of the business. Every business will use language peculiar to the company and the industry within which they operate.
These may come from documents that describe the business such as procedure documents, company policies and standards. They may also be sourced from business systems. The databases that contain the information used by the organization for example, will be a rich source of business terms.
Step 2 – Categorize
Typically, the identification stage uncovers a large number of business terms. Managing these in bulk will be virtually impossible so grouping and categorization is vital. Taxonomies – or schemes of categorization – can be created for topics which can help generalize terms and provide an easy mechanism to find them.
An example of one such categorization scheme in a manufacturing organization could be “Equipment”. In this example, “Computing Hardware” and “Machinery” could be sub-categories with a taxonomical relationship to “Equipment”.
Step 3 – Prioritize
Not all terms are equal. Some represent information that is more important to the organization. The terms that are used in important procedures and policies, or represent sensitive knowledge should be identified and marked accordingly.
Most organizations will attempt to identify the master data entities and critical data elements that are critical to the running of the business such as ‘Customer’, ‘Order’, and ‘Product’. These will often be the heads of taxonomy trees established in Step 2.
Such categorization makes it easier to mark groups of data entities – as opposed to individual data entities – as high priority when necessary.
Step 4 – Relate
Once a rank order of priority and taxonomical categorizations have been established, an organization’s data stewards can then capture the relationships between the concepts to form an ontology.
Ontologies help organizations reduce complexity and organize data. They help document the properties of data entities and how they are related by defining the sets of concepts and categories that represent the subjects.
For example a ‘Customer’ may have a ‘Customer Reference Number’. Loose relationships between those concepts can be demonstrated; a ‘Customer’ places an ‘Order’. An organization may also want to capture synonyms and identify preferred terms.
This allows data stewards to manage a single definition of a concept and then map synonymous terms back to the preferred term. Ontologies may also uncover some terms representing values that another term may take. Each value should have a clear definition that needs to be managed in the glossary.
Establishing and documenting ontological relationships between terms is vital in helping organizations understand and govern their data.
Step 5 – Define
At this stage, each piece of data is mapped, creating a clear definition of what each piece of information means. These definitions should be reviewed and approved by subject matter experts.
If these definitions didn’t exist, were incorrect, or ambiguous, a safety procedure that utilizes them could be insufficient.
Take a petrochemical company, for example. A safety procedure may state the following:
“In case of a broken drill chain, the fish should be removed before engaging the kelly. This should be performed only by the drill finger located in the dog house”.
While parties familiar with the industry may interpret the above as intended, terms like “fish”, “kelly”, “finger” and “dog house” have well-known alternative meanings and so introduce the potential for ambiguity.
Similarly, when making decisions based on data, all parties should have the same understanding of the meaning of that data. I.e. the “User”/“End-user” distinction above.
Step 6 – Classify
Once documented with details and definitions, each piece of data should be classified using a variety of systems such as personal data, confidentiality, value etc. Such classifications exist outside of the taxonomical categorizations mentioned above.
Typically, high scores indicate degrees of impact to the business. Personally identifiable information for example, would score highly within the “personal data” and “confidentiality” classifications.
Such classifications help organizations meet the requirements for data more efficiently. Of course, this has applications where an organization needs to identify and establish security around sensitive data and information. However, it also has implications for data access and data democratization.
In summary, effective classification of data helps make the right data available to the right people.
Once classified, data stewards can use the classifications to assign rules for data based on priority such as usage, data retention periods and quality standards.
Step 7 – Revise
Things change. Definitions change. Policies change. Rules change. An organization may even find that mistakes have been made. Therefore, a business glossary is never “complete” and needs to be managed via an iterative process.
Changes should be well controlled, as changes to definitions of some terms can fundamentally change documents that reference them such as company policies and procedures. A collaborative approach to iterating a business glossary allows changes to be reviewed and approved by the appropriate authorities.
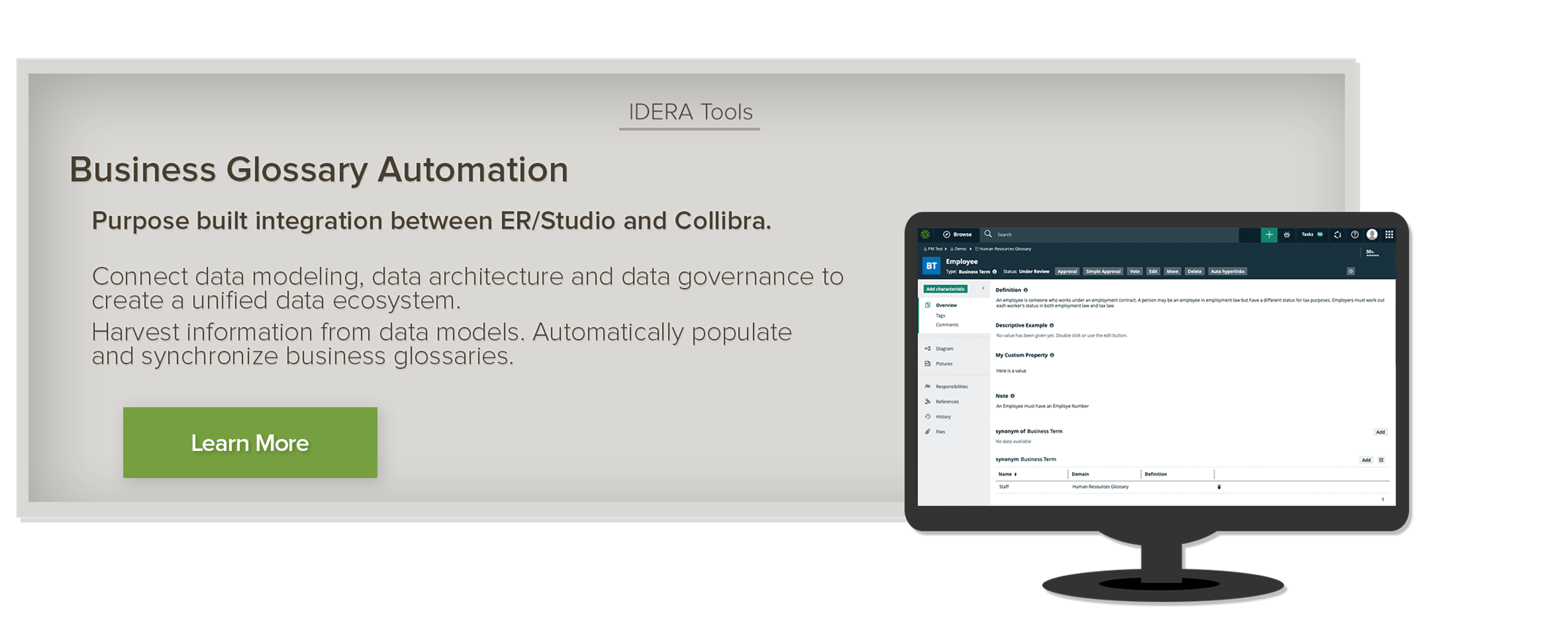
Business Glossary Automation
Business glossary automation provides organizations with a means to efficiently, accurately and comprehensively construct business glossaries. Typically, the most time consuming step for building a business glossary is the gathering and categorization of business terms.
However, data-driven organizations already have a well-informed source for business terms – their data models. These models are usually built using well-known business language and contain definitions and details regarding the relationships between terms.
For instance an enterprise logical data model should be semantically similar to the ontology within the prospective business glossary.
Business glossary automation allows data architects to quickly, easily and comprehensively harvest metadata from data models. It significantly reduces the need to manually populate business glossaries, instead allowing organizations to harvest business terms and ontological relationships directly from models.
This kick starts the creation of a well-organized business glossary, and helps maintain it going forward.
Tools for Business Glossary Automation
Organizations keen to take advantage of business glossary automation should look no further than IDERA’s flagship data modeling solution, ER/Studio.
ER/Studio is an enterprise tool for data architects to design and document data assets. Such documentation makes ER/Studio and the data architects that utilize it a great source for informing data governance initiatives such as constructing business glossaries.
Once constructed, ER/Studio also helps with business glossary management. The automation capabilities help support the iterative approach required to maintain the quality and integrity of business glossaries.
ER/Studio allows organizations to synchronize updates to the business glossary throughout the data ecosystem.
For example, changes to a term within the business glossary are synchronized to and reflected in logical models that include said business term.
Business terms and information can also be synchronized with an organization’s data catalog.
With the release of ER/Studio 19.1, Collibra users benefit from powerful, purpose-built integration between ER/Studio and Collibra Data Catalog. This allows business terms and ontological relationships to be harvested from ER/Studio and populated within the Collibra platform.
The integration is sophisticated enough to allow bi-directional synchronization between the two platforms, allowing changes in one tool to be reflected in the other.
By connecting data modeling and data governance in this way, helps organizations introduce a unified data ecosystem.