




Last week I was fortunate to be asked to present during the IDERA Live Event. There were many great presentations and those who attended received a lot of good information. I wanted to post a summary of my presentation here for those that were unable to attend.
In the blog, we are going to talk about how databases come to be. We will discuss the importance of data modeling in the design process, key concepts around design, data loading and finally some key elements of effective data management.
What is Data Modeling?
Unfortunately a lot of databases start as a gleam in someone's eye. Maybe consisting of a couple of tables needed to store some data for an application front end or perhaps generating reports or analytics. Soon a database is born and begins to grow as more data is added. It's somewhat like the big bang, from a small particle the universe is created.

Unfortunately over time we get to a point at which we are left with a pile of stuff.

Legos are great, but unless we build something useful or cool with them, it's just a pile of Legos. What we really want as a database is something like this:

It's fast sleek and really cool. This is what data modeling can do to help us design and build efficient, highly performing and relevant databases. The key benefits of data modeling are:
- Help build higher quality applications
- Reduce cost through design before coding
- Build software faster
- Determines scope of a project based on data needs
- Better performance of applications, data retrieval and analytics
If you want to sum this up in one thought, it's that data modeling does the work up front so you don't have to fix a mess at the end. In the next section we will talk about basic data modeling concepts.
Conceptual Model
A conceptual model is a high-level description of a business's informational needs. It typically includes only the main concepts and the main relationships among them.
Specifically, it describes the things of significance to an organization (entity classes), about which it is inclined to collect information, and characteristics of (attributes) and associations between pairs of those things of significance (relationships).
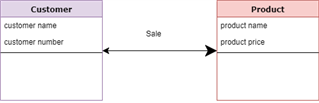
This type of Data Model is designed and developed for a business audience. The conceptual model is developed independently of hardware specifications like data storage capacity, location or software specifications like DBMS vendor and technology. The focus is to represent data as a user will see it in the "real world."
Logical Model
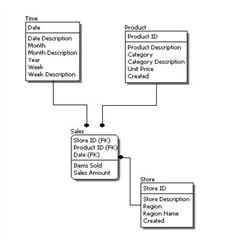
Logical data models should be based on the structures identified in a conceptual data model since this describes the semantics of the information context, which the logical model should also reflect. Even so, since the logical data model anticipates implementation on a specific computing system, the content of the logical data model is adjusted to achieve certain efficiencies.
As you can see here, the model includes all entities and relationships among them. All attributes for each entity are specified. The primary key for each entity is specified along with any Foreign keys (keys identifying the relationship between different entities). Normalization typically occurs at this level (for relational models).
Physical Model
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the life cycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation.
A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
Database Deployment
Deploying the database typically involves building the database from scratch on the platform to be deployed to. Deployment is usually built on the concept of "forward engineering". You can take the physical model in most data modeling tools and deploy/create the database.
To deploy, you can either use direct connection to the database platform or create “scripts” that can then be run to create the database.
New transactional databases (OLTP) typically have front end applications that are feeding data into the database. For databases built around the concept of Data Warehouse/Data Lake we typically find either:
- Extract, Transform, Load (ETL) which is normally a continuous, ongoing process with a well-defined workflow. ETL first extracts data from homogeneous or heterogeneous data sources. Then, data is cleansed, enriched, transformed, and stored either back in the lake or in a data warehouse.
- Extract, Load, Transform (ELT) is a variant of ETL wherein the extracted data is first loaded into the target system. Transformations are performed after the data is loaded into the data warehouse.
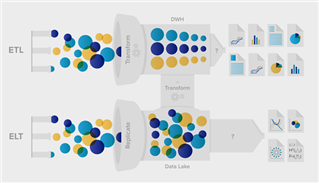
ELT typically works well when the target system is powerful enough to handle transformations. Analytical databases like Amazon Redshift and Google BigQuery are often used in ELT pipelines because they are highly efficient in performing transformations.
Typically, however, data is temporarily stored in at least one set of staging tables as part of the process.
The extract step might copy data to tables as quickly as possible in order to minimize time spent querying the source system, or the transform step might place data in tables that are copies of the warehouse tables for ease of loading (to enable partition swapping, for example), but the general process stays the same despite these variations.
Which is better depends on priorities. All things being equal, it’s better to have fewer moving parts. ELT has no transformation engine – the work is done by the target system, which is already there and probably being used for other development work.
On the other hand, the ETL approach can provide drastically better performance in certain scenarios. The training and development costs of ETL need to be weighed against the need for better performance. (Additionally, if you don’t have a target system powerful enough for ELT, ETL may be more economical.)
Some general guidelines on data loading:
|
Extract, Transform, Load (ETL) |
Extract, Load, Transform (ELT) |
|
Bulk data movement |
When ingestion speed is king |
|
Complex rules and transformations are needed. |
When more intel is better intel |
|
Combine large amounts of data from multiple sources |
When you know you will need to scale |
Finally
To sum things up, building, deploying and loading efficient and effective data platforms revolves around planning and modeling. If these things are done up front with the inclusion of the organization in the planning stages then we save a lot of headache and cost. I will leave you with this quote which pretty much says it all:
“If you do not know where you come from, then you don't know where you are, and if you don't know where you are, then you don't know where you're going. And if you don't know where you're going, you're probably going wrong.”
