Perhaps you just read the title and thought, “Disable indexes…say what?” Stay with me here, and I'll show you how this isn't as nutty as it seems.
Admittedly, one of the finest qualities a database professional can have is the quest for efficiency. Putting in the deep thought and hard work ahead of time allows us to “set it and forget it” and look like smarty pants the rest of the time.
However, you probably don’t want to set and forget an ETL process that goes something like this:
- Create a table (often some sort of data staging table) with a proper clustered index that gets truncated and reloaded regularly.
- Create one or more non-clustered indexes on that table to improve queries.
- Go about your business regularly truncating and reloading data in the table.
WHAT’S THE PROBLEM?
The trouble here is that even though I’m 99% sure your data that is getting inserted into this table is sorted in the same way as clustered index, I’m 100% sure it isn’t sorted in the same way as the supporting non-clustered indexes. And sorting, my friend, is expensive.
Let me demonstrate with a very, very simple ETL (or ELT) process. Actually, it’s just EL with no T, but you’ll get the idea.
First, let’s create a SourceTable table with one million records. Insert your own Dr Evil reference here.
USE tempdb;
SET NOCOUNT ON;
— create a source table
CREATE TABLE SourceTable (Id int PRIMARY KEY CLUSTERED, UpdateDate datetime2
GO — populate that table with 1,000,000 records DECLARE @id int =1 WHILE @id <= 1000000 BEGIN INSERT SourceTable (Id, UpdateDate) SELECT @id, getdate() SET @id += 1 END
Next, let’s create a second TargetTable table with the same columns as the SourceTable, as well as a supporting non-clustered index.
USE tempdb;
SET NOCOUNT ON
— Create a target table with a non-clustered index CREATE TABLE TargetTable (Id int IDENTITY (1,1) PRIMARY KEY CLUSTERED, UpdateDate datetime2
CREATE NONCLUSTERED INDEX NC01_TargetTable ON TargetTable (UpdateDate); SET STATISTICS IO ON
Lastly, let’s execute our pretend ETL process (which in this case will be demonstrated by a simple INSERT statement) that will copy the one million records from SourceTable to TargetTable. But in doing so, let’s be sure to check out the logical pages reads with SET STATISTICS IO. SET IDENTITY_INSERT TargetTable ON
SET STATISTICS IO ON
INSERT TargetTable (ID, UpdateDate) SELECT ID, UpdateDate FROM SourceTable; SET STATISTICS IO OFF
SET IDENTITY_INSERT TargetTable OFF
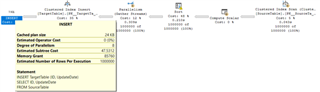
Here’s the execution plan, with an estimated cost of 155, mostly attributed to that big ‘ol 59% Sort operator for the non-clustered index. Ouch. Executing that takes about 4 seconds on my system, with 25,876 reads in our TargetTable. Table 'TargetTable'. Scan count 0, logical reads 25876 Let’s see if we can’t improve this. First some cleanup. TRUNCATE TABLE TargetTable; GO CHECKPOINT
GO WHAT’S THE SOLUTION?
Now, let’s do the whole thing all over again, but this time with disabling the non-clustered indexes before the INSERT and then rebuilding those indexes afterwards. You be thinking to yourself “I’ve rebuilt indexes, and they seem to take a long time.” Hold that thought and execute this. SET IDENTITY_INSERT TargetTable ON
SET STATISTICS IO ON
— Let's try the INSERT with the index DISABLED ALTER INDEX NC01_TargetTable ON TargetTable DISABLE
INSERT TargetTable (ID, UpdateDate) SELECT ID, UpdateDate FROM SourceTable; — …then REBUILD the non-clustered index ALTER INDEX NC01_TargetTable ON TargetTable REBUILD
SET STATISTICS IO OFF
SET IDENTITY_INSERT TargetTable OFF
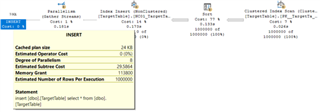
That took less than half the execution time for me, which makes sense since we doing a lot less work. The proof is in the pudding, and by pudding I mean the logical reads on our TargetTable, which are now down to 13,789 for the INSERT… Table 'TargetTable'. Scan count 0, logical reads 13789 …and 2608 for the index REBUILD. Table 'TargetTable'. Scan count 9, logical reads 2608 Add those two numbers together (16,397 reads) and we have a lot less than the 25,876 reads in the first example, every day and twice on Sunday. WHY DOES THIS PERFORM BETTER?
Although rebuilding an index seems like more work (it is work, after all) it’s less work because we’re not reading and re-arranging that non-clustered index while we’re inserting the records in the table. Instead, we’re doing one pass through after the insert into the table with the clustered index and then rebuilding that non-clustered index in order – and that, as you’ve seen, is much faster. Also, the execution plan is much happier now, using less resources and even going parallel in the index rebuild. Our estimated cost for the INSERT is now around 48… …and the estimated cost of the additional index REBUILD is only about 30. Those costs of 48 and 30 together make 78, which is about half of the 155 estimated cost of the INSERT without disabling the index. Good times all around now with improved performance for our ETL process! Summary Keep in mind this is with just one small index. Imagine there are even more non-clustered indexes (or even larger ones) that have to be re-ordered during the insert, and you can see how using the disable/rebuild method could improve performance even more than what we've done in this example! Oh, and one last thing. If you enjoyed this tip, you can find more like it in the recording of a Geek Sync session I previously gave on “Faster Transactions: Query Tuning for Data Manipulation”.