




Overview
Historically problems with application and database performance have often been addressed by upgrading hardware or database or even both. Adding faster CPUs and more memory could be seen as an easy fix and the database optimizer from each vendor has improved with each new release. But throwing hardware at a problem can only be a stop gap solution and optimizers are limited by schema design, the availability of up-to-date statistics and many other factors. Bigger and faster server purchases also resulted in larger data centers overloaded with servers each with its own high cost and carbon footprint.
With the advent of Cloud computing many companies have moved their resources to one of the different Cloud providers to avoid these costs. Doing this has made it possible to increase the capacity quicker and easier. However, if the VM/machine that the database runs on needs to be increased in size – CPU/memory then this still comes at an additional cost as the size of the VM increases.
There is another way. By carrying out performance optimization, we can reduce the need to increase the size of the VM/machine. Historically this was done by tuning the heaviest statements. Precise has a proven track record of providing alternatives to this approach; one of which is Object Optimization.
Many tuning methodologies tune one SQL statement at a time, adding indexes to cut down I/O and speed up the query. However each index has its own overhead; it consumes space and has to be maintained during update, delete, and insert operations. Each index also has to be maintained and sometimes rebuilt. Tuning at the object level has the power to benefit all SQL statements accessing the most resource hungry tables and can often deliver the required SLA performance much more quickly and at a much reduced cost but it’s important to get the cost/ benefit analysis right.
The Account Receivable process in PeopleSoft shop can incur performance issues and on occasion has been known to take longer than 24 hours to complete. Precise immediately spotted the bottleneck; sixteen indexes had been added to the AR table. Index overhead can be tough to analyze alongside statement performance with conventional tools but Precise was able to show the cost and benefit of each index, which indexes were used by the optimizer and which were not i.e. pure overhead. No other vendor was able to pinpoint the root cause and fix it so quickly.
This approach is similar for any DBMS that Precise supports, these include Oracle, SQL Server, Sybase and Db2. This article will talk about index optimization within Oracle Databases.
The formula is simple enough; The ideal index configuration for an application is to have the minimum number of fresh, highly selective, low clustering factor indexes, that are placed to minimize hardware contention
Identify the Contenders
The first step is to identify the tables which are contributing the most to overall SQL execution time. Using Precise, object tuning is a simple process; using accurate statistics gathered over time Precise can quickly identify the table access using the most resources and thereby contributing the most to any poor application performance.
The example below shows some JD Edwards tables with the busiest tables prioritized at the top.
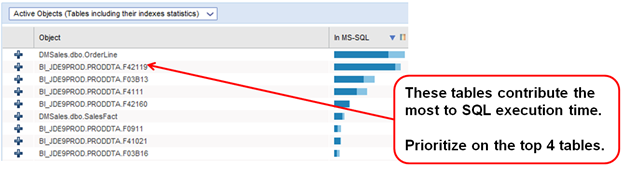
Once we have our candidate tables for tuning we can check each one against each of the criteria we identified for optimum indexing.
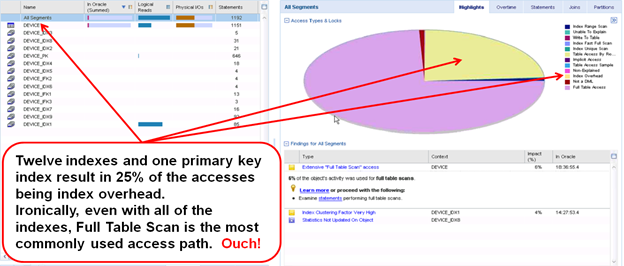
The above example shows the table has twelve indexes and a primary key index. Yet with all this indexing the most commonly used access path is still Full Table Scan and 25% of the access is Index Overhead. Precise’s intelligent ‘findings’ also show a very high Clustering Factor.
Clustering Factor is important
Clustering Factor is a number representing the amount of order of rows in the table based on the values in the index. Where all of the index entries in a given leaf block point to the same block in the table then the table is well ordered with regards to the index resulting in less I/O operations using the index for access. This is a low clustering factor.
When all of the index entries in a leaf block point to different blocks in the table then the table isn't very well ordered which will result in more I/O operations using this index for access. This is a high clustering factor.
If the value is near the number of blocks, then the table is very well ordered. In this case, the index entries in a single leaf block tend to point to rows in the same data blocks. If the value is near the number of rows, then the table is very randomly ordered. In this case, it is unlikely that index entries in the same leaf block point to rows in the same data blocks.
Precise will show you the Cluster Factor for each index of the table.
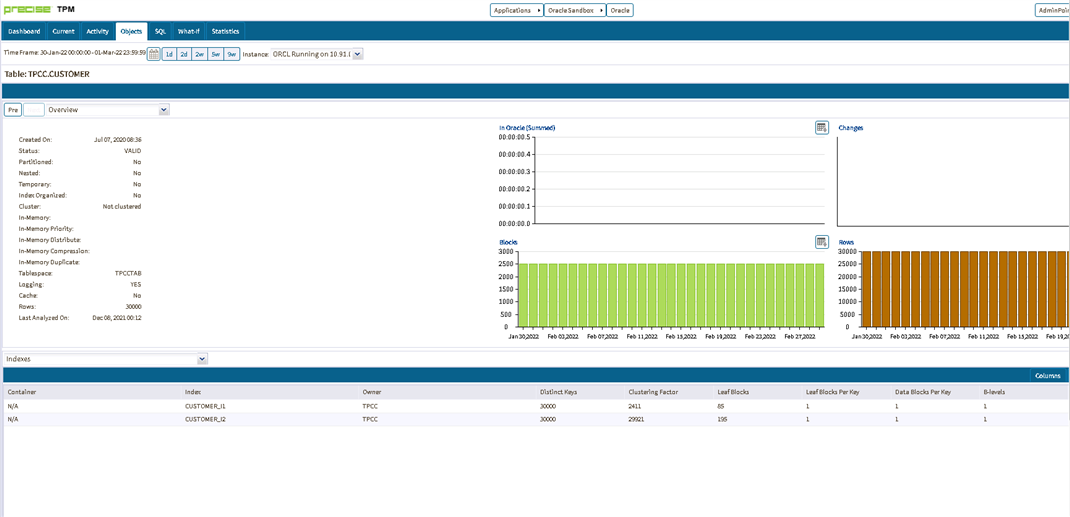
By keeping the Cluster Factor for an index low we can persuade the Cost Based Optimiser (CBO) to use this rather than a Full Table Scan. However, Oracle can miscalculate the Cluster Factor especially when inserting rows into a table using Automatic Space Segment Management (ASSM).
We may have to force the Cluster Factor to be low by using either TABLE_CACHED_BLOCKS statistic factor or Attribute Clustering.
TABLE_CACHED_BLOCKS tells Oracle not to increment its block-change counter if the latest table block address matches one from the recent past. A max value of 16 is recommended for this.
ATTRIBUTE CLUSTERING is a table-level directive that clusters data in close physical proximity based on the content of certain columns. Storing data that logically belongs together in close physical proximity can greatly reduce the amount of data to be processed and can lead to better performance of certain queries in the workload.
Unused Indexes
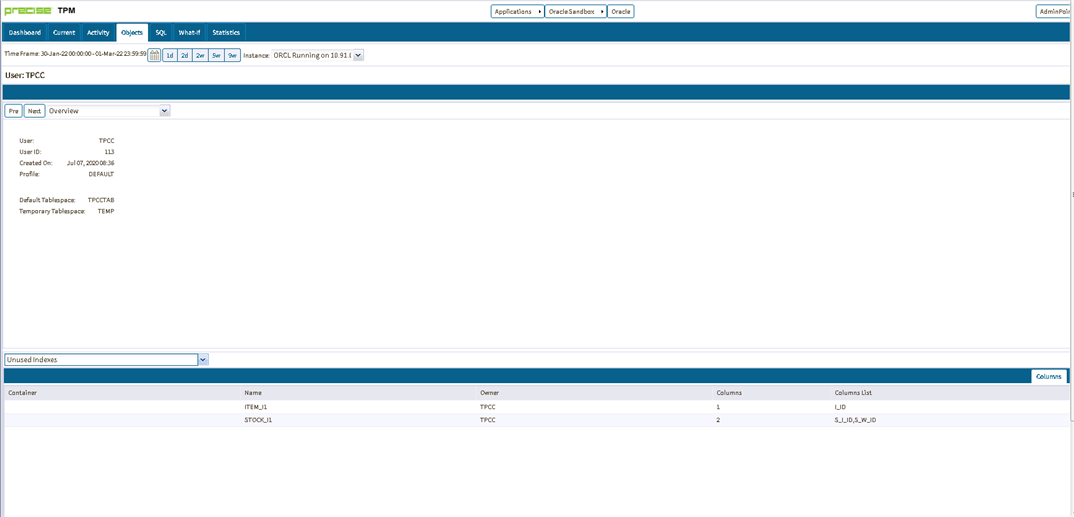
Historically ERP solutions have large number of indexes created on tables. It is likely that many of these indexes are not used by the application.
Precise provides a way to identify those unused indexes. It is then possible to look at removing those indexes and eliminate excessive index overhead. Testing should be carried out before this is done in a production environment.
Have Highly Selective Indexes
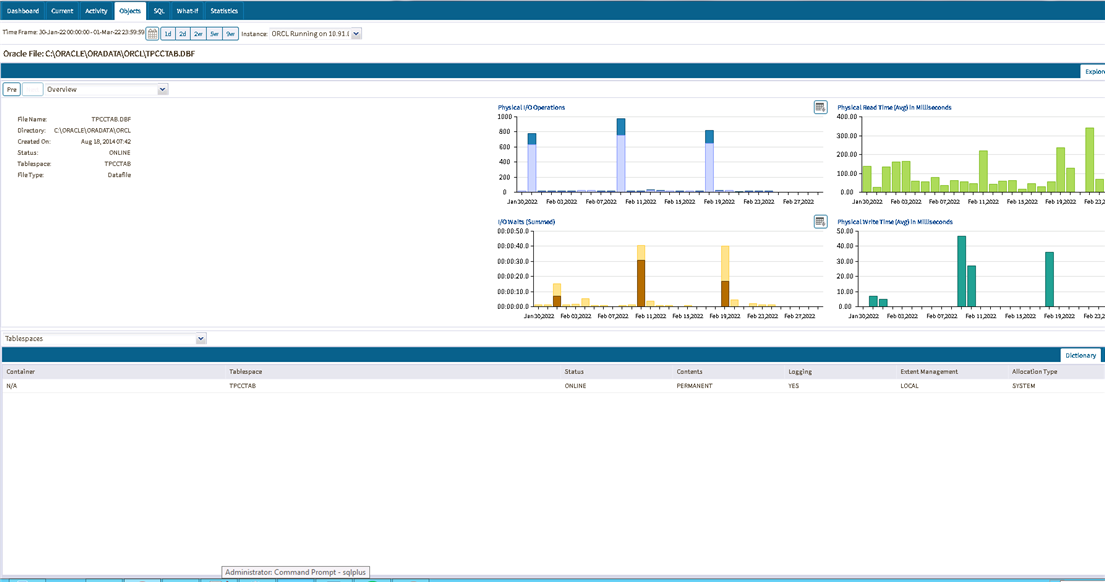
Executing SQL statements are either working or waiting on a resource. Precise measures the contribution made by I/O access to the object on the oracle data file and aggregates it into the category “I/O wait”. Where appropriate this includes the entire SAN roundtrip time. In the example below the majority, approximately 90%, of the execution time is spent waiting on I/O.

The I/O wait time is the time spent accessing the oracle data file(s). This high I/O wait time could be due to a number of different reasons.
- A large amount of I/O because the execution plan is poor and as a result too many blocks qualify and need to be loaded into the oracle buffer.
- Slow I/O which could be a result of slow read I/O from the oracle data file.
You can use the Tune functionality of Precise to show the execution plan for the SQL query and identify possible recommendations.
Precise can also show I/O activity for the Oracle database files which will help indicate if you have a storage problem with slow read I/O
Summary
ERP applications can often be delivered with default indexing and insufficient maintenance routines to keep the execution plans and indexes healthy. Indexing can quickly become out of date as applications evolve and as users begin to write their own reports and queries. Tuning at the object level across the database as part of a pro-active performance management policy is the best way to keep databases performing at their optimum and to head off any potential performance cliffs that are on the horizon. The comprehensive and valuable data stored inside the Precise Performance Management Database (PMDB ) as accessed via the GUI and simple to use dashboards, reports and alerts speeds up this process and provide a valuable return on your investment in the quickest possible time.