Database security is a hot topic these days, especially with all the new and seemingly never-ending security compliance requirements being imposed such as GDPR. This means that DBAs must up their game when it comes to database security. Some DBAs may think these new requirements apply only to production, but depending on the situation DBAs may well need to apply tauter security across the board – including development and all test databases (e.g. unit testing, stress testing, and acceptance testing). This blog covers some very simple database security checks which are easy to deploy and which at least start you on the road to better security. While the examples shown are for Oracle, the security concepts and thus techniques should apply equally well across all other database platforms. You may just need to translate the concepts and example scripts shown here to your specific database platform.
Note that for many examples I will be using the powerful, multi-database GUI tool: Aqua Data Studio.
Each week I will post four simple, yet worthwhile database security ideas. Part one, Part Two, and Part three posted the last couple of weeks covered the first twelve security ideas. This blog now picks up with the next set of four security ideas.
Issue #13 – Don’t Use the Default Network Port
One of the easiest and yet often overlooked security risks is not changing the databases’ assigned network port. Below is a table of the well-known default network ports for many popular relational databases. This is often one of the very first security holes any hacker looks for. Sometimes just by overlooking the default network port and the default database passwords (mentioned in last week’s blog), hackers are able to gain access. Even if you do have all the default database passwords locked down, hackers can sneak in via the databases’ network default ports to apply “password crackers” or simply launch Denial of Service (DOS) attacks. While you might believe that everyone changes these, the reality is that many do not. In Part one I mentioned my friend who is the DBA director of a SQL Server shop is enduring a security compliance audit and the second major hurdle he ran into was the all the databases were using the default network ports. Moreover, many of their application code and scripts had hard-coded their connection logic using those values. This security risk is simple to fix and provides the first major impediment to outsiders gaining access, so it should always be done.
|
Database Platform |
Default Network Port |
|
Oracle |
1521 |
|
SQL Server |
1433 |
|
MySQL |
3306 |
|
PostgreSQL |
5432 |
|
IBM DB2-LUW |
50000 |
|
Sybase ASE |
5000 |
Issue #14 – Separate Schemas from Users / Logins
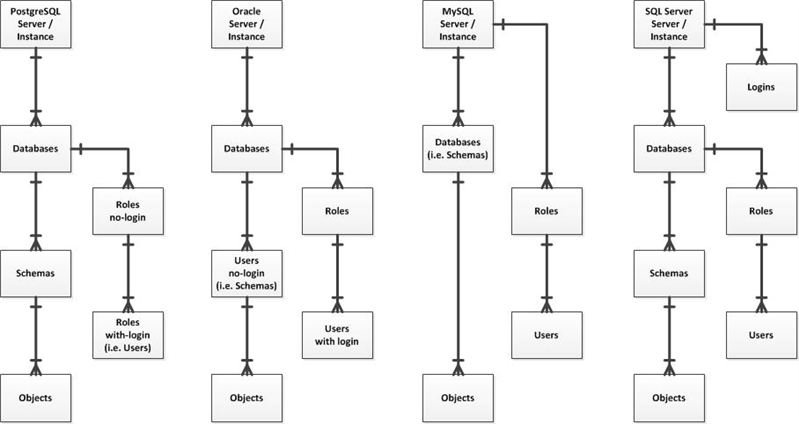
The security architectural design varies across the top four database platforms as shown in the diagram below. One key concept they all offer is a collection mechanism to own all the persistent objects such as tables and indexes. Moreover, these collections or “schemas” are not for connecting to or logging in. The basic premise is to separate ownership from access. However, I encounter many applications developed where the entity owning the objects is also the entity with the login credentials provided to access those database objects. My point is that all of today’s key databases offer robust security models which should be properly leveraged. It’s time to fully separate schemas from users and/or logins. It’s also time to stop using one login for the entire application lest database auditing and performance diagnostics efforts will be compromised by not having different connection details to help identify who is causing any issues.
Issue #15 – Consider Implementing Row Level Security
Most databases support some mechanism for implementing row level security, which is restricting data access to rows based upon the user. In the old days, we had to accomplish such security utilizing views, which were not as easy as with newer features directly supporting row level security. Let’s assume that you’re using PostgreSQL 10.X and have a DEMO schema with an EMPLOYEE table as defined here:
create schema demo;
create table demo.employee (
emp_id integer,
fname varchar(10),
lname varchar(20),
salary money,
mgr_id integer,
primary key (emp_id),
foreign key (mgr_id) references demo.employee(emp_id)
insert into demo.employee values (1,'Stan','The Man',150000,null);
insert into demo.employee values (2,'Ron','Mr. ERD',140000,1);
insert into demo.employee values (3,'Kim','Ms. Parser',130000,1);
insert into demo.employee values (4,'Lisa','Mrs. DBMS',120000,1);
select * from demo.employee;
emp_id | fname | lname | salary | mgr_id
——–+——-+————+————-+——–
1 | Stan | The Man | $150,000.00 |
2 | Ron | Mr. ERD | $140,000.00 | 1
3 | Kim | Ms. Parser | $130,000.00 | 1
4 | Lisa | Mrs. DBMS | $120,000.00 | 1
(4 rows)
Next, you’d have to create a database user/login for each employee contained in the EMPLOYEE table and define the basic grants to allow them to see the table. Note the SECURITY role was created such that you can perform all necessary grants once per object on it rather than for each object and each user.
create role security with nologin;
create user stan with password 'stan' in role security;
create user ron with password 'ron' in role security;
create user kim with password 'kim' in role security;
create user lisa with password 'lisa' in role security;
grant usage on schema demo to security;
Finally, you can create a rather simple view which allows each person to see only their own rows of data, remember you have to include a grant for this new database object for users to have access. There are three major items to note here. First, you do not grant access to the EMPLOYEE table to anyone. Access is restricted to the view. Second, the UPPER function was used to restrict the rows returned to just those of the connected user. This is purposefully an overly simple example. In reality, you would implement far more sophisticated logic. Third, if you were asked to create many such security policies then you’d have lots of grants throughout your database. So while this technique works, it adds complexity to all the grants. Plus if you had to grant direct access on EMPLOYEE table to the SECURITY role for some other reason, then any user smart enough to query using the table name instead of the view would see data they’re not supposed to.
create view demo.see_myself as
select * from demo.employee where
upper(fname)=upper(session_user);
grant select on demo.see_myself to security;
However, this technique does work, as shown below where we login as “lisa” and query the view as intended.
C:\Temp>psql -d demo -U lisa
Password for user lisa:
demo=> select * from demo.see_myself;
emp_id | fname | lname | salary | mgr_id
——–+——-+———–+————-+——–
4 | Lisa | Mrs. DBMS | $120,000.00 | 1
(1 row)
It’s actually far easier these days with most databases to implement row level security leveraging their built-in capabilities as shown here.
create policy see_myself on demo.employee using
(upper(fname)=upper(session_user));
grant select on demo.employee to security;
Now you might well argue that this solution is two lines just like the prior, so why is it considered better and/or easier? Frist, even though we grant direct access on EMPLOYEE table to the SECURITY role users still only see their data. As such, no hidden loophole exists as with view in the case the table accidentally got granted. Second, we can drop and create policies without breaking the application code. Everyone is accessing the table which has a grant. The only thing changing is the policies and the effect they have on the runtime results returned. Finally, if we needed 20 such security policies we would not have to do an extra 20 grants as with the views. So this method makes security management less tedious.
Issue #16 – Consider Implementing Data Encryption
Most databases support some mechanism for implementing transparent data encryption, which at a minimum is the encryption of data on disk (i.e. data at rest). Some databases can even keep the data encrypted in RAM memory and network packets (i.e. data in motion). No matter which, this is all done seamlessly and transparently to the end users. They just see the data as they are accustomed to, it merely will have been safe and secure from disk and/or in transit to them without their even knowing it.
Of course, there is some overhead to having the database engine encrypt and decrypt the data every time it’s written or read. But the security benefits more than offset that cost, especially given today’s extremely powerful CPUs and GPUs sometimes used to augment the CPU (even in some cloud setups). When MariaDB version 10.1 which offered such encryption first debuted, I actually did the database benchmarking for the overhead cost for the database vendor’s marketing department. The costs were so low as to almost not be worth mentioning (i.e. approximately 2-4% depending on the data’s nature and size).
Finally note that some databases offer column-level encryption, some offer table level and column level, others offer it at the file or tablespace level, and yet others offer it for the entire instance. Furthermore, some databases offer encryption for free while others require a specific edition or an extra add-on. Here are a few simple examples of encrypting tables or columns just to show how it’s done (and how easy it can be).
|
MySQL |
CREATE TABLE table_name (…)ENCRYPTION=’Y’; |
|
MariaDB |
CREATE TABLE table_name (…) ENCRYPTED=’Y’; |
|
Oracle |
CREATE TABLESPACE ts_encrypted DATAFILE … ENCRYPTION ENCRYPT; CREATE TABLE table_name (…) TABLESPACE ts_encrypted; |
Until next week when then, when we will delve even deeper into basic security techniques to harden your databases against attack. Hopefully, by now you’ve begun to see that the net or cumulative effects of all these ideas will shore up your database security. And best of all, all these recommendations are all very easy to implement.