Do you like hammering nails with screwdrivers? Me neither, but all too often we take this kind of approach when writing our SQL queries. We use the wrong tool for the job, and consequently end up consuming more time and resources to do a simple task.
This process of repeatedly doing more work than necessary is often described as a query “antipattern.” For those who aren’t familiar, the word “antipattern” refers to a phrase coined years ago in a SQL book by Bill Karwin, and it describes a commonly used technique (that’s the “pattern” part) to solve a problem but often inadvertently leads to other problems (that’s the “anti” part.) And by “other problems,” we often mean poor query performance from doing more work than necessary.
How do these antipatterns happen? Well, usually it’s because most of us have a limited set of SQL commands that we rely on to perform various queries. Unfortunately, we often end up using inefficient commands because we don’t know there are more efficient commands available. Much like using a screwdriver to hammer a nail, we take comfort that the tool works, even though it's definitely not the best tool for the job.
Today I will show you an example of one such antipattern, and I dare say it is one that most of us have used many, many times.
WHAT WE OFTEN DO
Imagine a scenario where we need to find the results of one set of data that don’t exist in another set. For example, a list of names of people in our database for whom we don’t have an address. Using the “AdventureWorks2019” database for this scenario, I would suspect many of us would instinctively write a query like this:
SELECT p.FirstName, p.LastName
FROM Person.Person p
LEFT OUTER JOIN Person.BusinessEntityAddress a
ON p.BusinessEntityID = a.BusinessEntityID
WHERE a.BusinessEntityID IS NULL
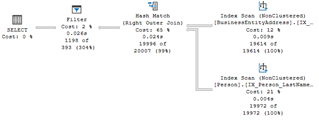
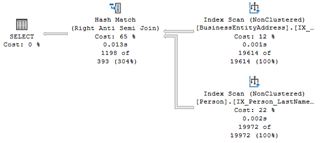
Effectively, we want a result set that shows us the FirstName and LastName of everyone IN the Person.Person table who is NOT IN the Person.BusinessEntityAddress table. To get this result set, we use the trusty LEFT (OUTER) JOIN combined with WHERE a value in the joined table (in this case BusinessEntityID) is NULL. In other words, we are asking SQL Server to match all the data and then give us whatever IS NOT IN the joined table. This can be verbally expressed this as “What’s in here that isn’t in there.” This is a great idea and it does work, but… the problem is we’re asking SQL Server to do something we don’t really care about, which is to match all the data. Matching all the data is what JOINs do. Moreover, after doing all that matching, it has to take the additional step of deciding what didn’t match from the first table and discarding all other records. This is a lot of extra work to just figure out “what’s in here that isn’t in there,” and that’s what makes this an antipattern. Let’s take a look at the execution plan for our query. Just to acknowledge, yes, SQL Server did turn our LEFT OUTER JOIN into a RIGHT OUTER JOIN, but that’s not really important. It just decided it wanted to read the tables in a different order. That’s just SQL Server being SQL Server. What IS important though, is this: in that Hash Match (Right Outer Join) we see that SQL Server read and MATCHED 19,996 records, and at that point we’re at .024 seconds. Then, after all that matching, it had to use the Filter operator to find the values that matched as NULL in the second data set, bringing the total execution time to .026 seconds. I realize .026 seconds isn’t exactly a lot of time, but we’re only dealing with a final result set of 1198 records. (It says “1198” right there in the Filter operator.) But beyond this example, we often find our ourselves dealing with a result set exponentially larger than this, so we will definitely start feeling the performance pain of this antipattern. WHAT WE SHOULD DO INSTEAD Alright, let’s resolve this query antipattern. First, let’s go back to verbally expressing what we really want. “What’s in here that isn’t in there,” which we can also express as “What exists in here that doesn’t exist in there.” Therein lies the solution: using NOT EXISTS. And so, we rewrite the query accordingly. SELECT p.FirstName, p.LastName FROM Person.Person p WHERE NOT EXISTS ( SELECT 1 FROM Person.BusinessEntityAddress a WHERE p.BusinessEntityID = a.BusinessEntityID); This is more efficient because we end up using a Semi Join operator (actually in this case it’s an Anti Semi Join), which only matches the first occurrence (or in our case, the absence) of a value. Our new query doesn’t match all the data, but rather only looks for the existence (or absence) of a value in the secondary data set – which is all we really wanted. Here’s the execution plan for the new query. Unlike the Right Outer Join in the previous query that matched nearly 20,000 records, our sleek Right Anti Semi Join only matched 1198 records, which is exactly the number of records in the final result set (no additional Filter operator needed!) Consequently, the query executed in .013 seconds, which half the time of the antipattern query. Note that although we can’t explicitly write a command for Semi Joins or Anti Semi Joins, we can invoke them by using SQL commands like EXISTS/NOT EXISTS, SOME/ANY, IN, and INTERSECT. If you’re not familiar with any of these, then now is a great time to add them to your repertoire so you can use them appropriately to evaluate the presence (or absence) of values between data sets. Oh, and one final note: if you found this post valuable, please register for my Geek Sync session “Breaking Bad Habits: Solutions for Common Query Antipatterns” on March 3rd. I’ve got several more solutions to these kinds of SQL antipatterns that I can’t wait to share with you!