Back in 2012, I had the pleasure and privilege of working with one of the sharpest developers I’ve ever met. He was a .NET lead of the application development team and I was a BI guy responsible for developing the backend database. Over the course of this 8-month project, thanks in large part to Jonathan, I was introduced to 2 very-cool technologies: SQL Server Service Broker and the SQL Server Database Project. The first provided me with a very new and interesting way of designing reliable asynchronous batch processing solutions, while the latter changed my life forever.
The goal of this blog post is to introduce you to the SQL Server Database project, convince you that it is a better (maybe the best) way to develop databases, and possibly change your life forever.
What is a SQL Server Database Project?
In simple terms, a SQL Server database project is just a collection of SQL files wrapped up inside a Visual Studio project that, together, define the structure of a SQL Server database. Each major database object – every table, view, stored procedure, function, everything – is defined as a CREATE-statement in a separate file. Where things get magical is when you unlock a bundle of development-oriented capabilities via tight integration with the following 3 components:
- Data-Tier Application (DAC): a self-contained unit of SQL Server database deployment that enables data-tier developers and database administrators to package SQL Server objects into a portable artifact called a DAC package, also known as a DACPAC.
- SQL Server local database runtime: a shadow SQL Server instance that runs in the background of your workstation and upon which the DACPAC can be instantiated into a full blow SQL Server database.
- SQLPackage.exe: a utility that automates several development tasks such as creating, comparing, and deploying a DACPAC.
Together these components allow you, as the developer, to treat the database as if it was an application. As someone who took a handful of Java/C/C++ programming classes back in high school and college but focused primarily on databases and SQL ever since, the concept and associated advantages of viewing the database as an "application" were not immediately self-evident. However, I can assure you that 1) the advantages are many and 2) the methodologies and tooling for application development are way ahead of those for database development.
Benefits of using a SQL Server Database Project
Before diving into the "how", let's take a moment to explore and appreciate the "why". As mentioned earlier, there are many benefits of using a SQL Server Database Project. Here are a few of the most important…
- Declarative Programming & Idempotency
Using a SQL Server database project is a declarative approach to database development where you "declare" the structure of the database. Every major-object (i.e. tables, views, stored procedures, etc) is defined as a CREATE statement in a separate SQL file. Need to add a column to a table, just update the CREATE table statement. There's no need to write and/or manage the order of any ALTER statements. That complexity is handled for you!When you need to deploy your database project, SQLPackage.exe does all the heavy lifting of determining what changes need to be made (and in what order) to make the target look like what has been "declared". This is what makes the SQL Server database project "idempotent"… whether you're deploying the database for the first time or deploying a new set of changes to an existing SQL Server database, the result is the same. You end up with a database that matches what has been defined in the project.
- Making Changes (aka Refactoring)
Like death and taxes, you can be certain that the structure of a database will change over time. The complexity of the changes can vary greatly. Need to change the data type of a column from INT to BIGINT or VARCHAR(10) to VARCHAR(20), no big deal. Need to rename a column in a table that is referenced by several views and a handful of stored procedures? Different story.Sure, SQL Server Management Studio (SSMS) can list dependencies. However, from the perspective of a developer, where the context is typically to generate an impact analysis and then update the dependent objects, the SQL Server database project approach is far superior.
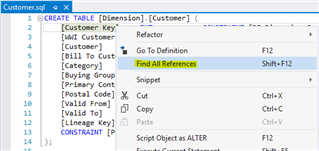
First, there's an option to "Find All References". This can be run on nearly any object in the database, even minor ones such as a column.

In the screenshot above, I've right-clicked on the [Customer Key] column of the [Dimension].[Customer] table. If I were to then choose "Find All References" a list would be generated containing every instance where this column was referenced. I could then double click an item from the list and immediately update that object if needed. However, if the intent is to make a change that would require corresponding adjustments to the dependent objects, you'd be better off using a refactoring-specific feature like the ones shown (in red) below…

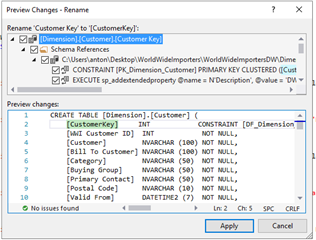
The first 2 options (Rename, Move to Schema) will not only allow you to make the change to the immediate object but they will also propagate the change to all places in the code where that object is referenced.
For the "Rename" option, consider the scenario where you would like to rename a column that's referenced by several stored procedure. Renaming the column through this mechanism will allow you to update the column name in both the table definition and all places in the stored procedures that reference that column.

If you just change the column name manually in the create table statement, the stored procedure will still reference the old column name and cause an error when you try to build the project. The "Move to Schema" option works the same way but applies to moving major objects (e.g. table, views, etc.) to a different schema along with all references.
The other 2 refactoring options (Expand Wildcards, Fully-qualify Names) are related to "code quality". The first option, "Expand Wildcards", will replace the asterisk in any "SELECT *" with the list of actual table columns, while the second option, "Fully-qualified Names" will prepend the schema to standalone table references. Both changes are considered "good practice" as they help avoid potential ambiguity and remove the risk of implicit dependencies. More on this in the next section.
- Database Code Analysis
In addition to the 2 refactoring options mentioned at the end of the previous section, SQL Server database projects include a feature called Database Code Analysis that runs through a list of "rules" and flags issues related to syntax, naming conventions, and even potential performance issues.The list of rules can be edited or even extended with custom rules to meet the specific needs of the development team. Below are a few of the built- in rules…
- Avoid Select * in stored procedures, views, and table-valued function
- Data loss might occur when casting from DataType1 to DataType2
- The name that you specified for an object might conflict with the name of a system object
- The name that you specified will always need to be enclosed in escape characters (in SQL Server, '[‘ and ‘]')
- Avoid using patterns that start with "%" in LIKE predicates
- Schema-Compare
This feature enables developers to compare the SQL Server database project with another SQL Server database and generate a list of differences between the two. The developer can then, with the simple press of a button, generate a change script that can then be run on the target database so that it matches the source database.This feature can be incredibly useful in many scenarios – the most obvious being the need to move a change from your development environment over to the QA environment for testing. It can also be used in reverse order where the SQL Server database project is the "target" and an existing database (e.g. Production) is the "source". If you've ever had to make changes (e.g. fix a bug) directly in a Production environment, this is an easy way to make sure the changes related to the "bug fix" get brought back into source code so that the "bug" isn't reintroduced during the next release cycle.
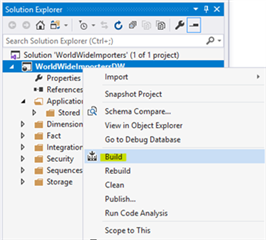
- Clean, Build, and Rebuild
In visual studio, building (or rebuilding) is roughly synonymous with "compiling" the code. The output of this process depends on the type of project. For a SQL Server database project, the output is a file called a DACPAC. We'll get to the benefits of the DACPAC it a bit, but for now, just know that in order for the build/rebuild to complete successfully and the DACPAC to be generated, all the SQL code used to define database (tables, views, stored procedures, etc) must be free from errors.
To give you an example of why this is important and not so obvious, imagine the following scenario where the steps below are carried out in order over the course of several days. Perhaps a contrived example, but I assure you this sort of scenario is very common when multiple developers are working on the same database on shared development server and not using a SQL Server database project.
1. create 2 tables
2. create a view that joins both tables
3. drop one of the tablesAt this point, the code is broken. Step 3 is 100% error free and provides no indication, warning or otherwise, that the view created in step 2 no longer works. In fact, it isn't until you actually try and query the view that you realize there's an issue. If using a SQL Server database project, the issue would have been immediately found when you "build" the project after step 3.
Build often – and always before checking in code!
- Version Control
Version control is a fundamental cornerstone to good development practices, and yet not everyone is using it to manage the database code. And of the groups who are using version control to manage the database code, many are simply using it as a place to store an assortment of "custom SQL scripts" that, when run in a specific order will advance the state of the database from the starting point at the beginning of the development cycle to a new state which includes some features and bug fixes.Using a SQL Server database project unlocks a whole bunch of helpful features available in most (all?) modern day version control platforms (e.g. Git, TFS, etc) such as historical change tracking, comparing different versions of an object, and the ability to roll back to a previous version of the database.
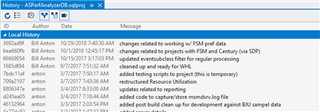
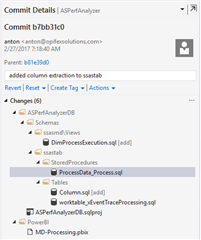
Below is a screenshot showing the development history of a SQL Server database project I was working on several years ago…

Each one of those lines represents a change (or set of changes) made to the database project. From here I can choose one and review the actual file(s) changed…

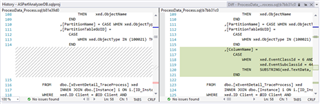
For each file, I can compare with any other version to see a side by side breakdown of the differences…

There's also the ability (again, in most cases) to establish "rules" that are run upon each committed change. For example, if the project doesn't build, the code will not be committed. Some shops take this much further and build out a "continuous deployment" process that (upon checking in a change) will automatically build the project, deploy it to test environment, and run a set of tests to ensure the database code is both syntactically and functionality correct.
BTW: IDERA offers a versatile tool for rolling out and tracking database changes for SQL Server, Oracle Database, Sybase ASE, and Db2: DB Power Studio

Wrapping Up
Congratulations if you’ve made it this far!
Hopefully, you are now strongly considering how best to start using SQL Server database projects for current or future database development. There are many considerations that have been left out such as handling database users and roles, pre and post deployment scripts, and references and project variables, and many other areas that need to be fully considered and understood before diving in head-first into the deep end.
As with any new technology, it’s best to start small and build a comfortable working experience. A good place to start that process is the World-Wide Importers sample dataset (which can be found here).