
Welcome! Last time we looked at the architecture of a simple calculator app, showing how to design an application well by separating the UI and logic, abstracting through interfaces, and ensuring each class had a single responsibility. That's important stuff, stuff that many developers skip, and is really important. Now we've done that, though, we can dig into the actual code. Today's blog post is almost entirely code, and will introduce you to several very interesting C++ concepts and techniques.
Important note: We’re going to use Boost, the most common C++ library. It’s available through GetIt and is large and it takes some time to install, so I’d suggest installing it while reading through this blog post. Open the IDE, go to the Tools menu, GetIt Package Manager, type ‘boost’ into the Search field, and when it appears, install it. For the Clang-enhanced compilers, we ship Boost 1.55, and the same installer will install an earlier version (1.39) for the old, ‘classic’ compiler (which as we read earlier, you should not use, since it's previous-generation technology.) You will need to restart the IDE afterwards.
Part I: Connecting the UI and calculator, and object ownership
The code as it stands has a form, an interface representing a UI that can display results which the form implements, an interface representing a calculator, and a skeleton calculator class implementing that interface.
There are a couple of changes to the interface from last week: Equals is not an operator, but an operation, so remove it from the enumeration of operations and add a method to the ICalculator interface: void Equals(); It doesn't need to return anything because it's just for the UI to tell the calculator that Equals was pressed: results are displayed through the ICalculatorDisplay interface.
The form and the calculator need to know about each other. However, also important is the concept of ownership – which object controls the lifetime of the other? Here, the form is going to own the calculator, so the calculator will be created when the form is and be destroyed when the form is.
Ownership is important for several reasons:
- Preventing memory leaks. You want an object to exist for only as long as it needs to exist. You don’t want it to be created and forgotten about (a leak) and you don’t want it to be created and kept around longer than required (wasted resources).
- Clear program logic. Suppose the calculator object wants to ask the UI to print something, but it’s not sure if the UI exists or not. It will have to check if it has (say) a null pointer instead of a valid pointer before trying to access the UI. That doesn’t make sense; better for it to be guaranteed that the UI exists. If the form owns the calculator, the calculator knows that if it is alive, the UI is alive.
Similarly, since the form needs the calculator object for its lifetime (if the form exists, someone might press buttons and do calculations) so it too knows that it can always access its calculator object without checks. A guarantee like that isn’t required – often it’s very valid for something to maybe not exist, and in fact we’ll examine several cases like that very shortly. However, strict and clear ownership makes the rules of what exists when clear, avoiding crashes or other bugs.
Let’s first look at the calculator. It is owned by the form, and if it exists, the form is guaranteed to exist, so we can give it a reference to the UI (the form, through an interface.)
Remember, a reference is like a pointer that is guaranteed to exist, and the syntax is like a normal object (eg foo.bar()) not like a pointer (which would be foo->bar()).
To avoid leaking details about the concrete implementation, rather than the interface, we’ll create it through a factory method, so add one to the uInterfaces.h and .cpp file.
In the header:
. ICalculator* CreateCalculator(ICalculatorDisplay& Display);
and in the implementation:
.
#include "uInterfaces.h"
#include "uCalculator.h"
ICalculator* CreateCalculator(ICalculatorDisplay& Display) {
return new TCalculator(Display);
}
It accepts a reference to the UI, and creates a calculator returning a pointer (it is created on the heap; the Type-asterisk syntax indicates the type it returns is a pointer to Type.) Note that this hides the existence of the calculator class completely – the form never has to #include it. That’s good design; things are abstracted behind interfaces and unaware of the actual implementations. In the calculator class, add this constructor and store the member reference:
In the header:
.
class TCalculator : public ICalculator {
private:
ICalculatorDisplay& m_Display;
public:
TCalculator(ICalculatorDisplay& Display);
...
and in the implementation:
.
TCalculator::TCalculator(ICalculatorDisplay& Display) :
m_Display(Display)
{
}
Smart pointers
More interesting is the owning object and how it owns the calculator.
C++ allows raw pointers, and old C++ code often uses them liberally. They lead to problems:
- You have a pointer. What has to delete it (free it) and when? How many other objects have a copy of this pointer, ie are relying on it not being freed/deleted? This is ownership and lifetime
- You have a pointer. Is it valid? What if it was deleted, but never set to null – you have an invalid pointer where accessing it will crash. How do you know? This is validity
Smart pointers are an answer to these two problems. (Other languages solve it with automatic reference counting (ARC) or a garbage collector (GC); both these effectively rely on a reference count or discovering the number of active uses of an object. C++ allows you to refcount if you wish, but also to use other patterns.)
Smart pointers are classes which manage the lifetime of pointers. They own a pointer, and they delete it. Because you know how they behave, you can use them to own a pointer and have guarantees about its lifetime and validity. Normally, they take ownership when they are created, and delete the pointer (or decrement a refcount, etc) when they are destructed. This is particularly useful for using them as members of a class – when the class destructs, the pointers it owns are automatically deleted (or refcount decremented) too – or stack-allocated in methods, because when the smart pointer goes out of scope it is destructed, it will automatically delete (or decrement a refcount) the pointer it owns. There are two types in C++11:
- shared_ptr. This keeps a count of how many places are accessing the pointer, and the pointer is only deleted once the last reference disappears and the reference count drops to zero. Use this when many objects need to refer to a pointer and the pointer’s lifetime can end when the last shared_ptr referring to it is destroyed.
- unique_ptr. Only one owner of a pointer is allowed. When the unique_ptr is destructed, the pointer it owns is deleted.
What does this mean? It means you never use the delete (freeing) keyword in your code, and you never manually manage pointer lifetime.
Destruction vs deletion
What is the difference between destruction and deletion?
Deletion is when a pointer is deleted or freed. That is, in the code:
. Foo* foo = new Foo(); delete foo;
An object of class Foo is created on the heap, calling its constructor; a pointer is returned; that pointer is deleted, and that destroys the object calling its destructor. That is, deletion is one mechanism to destruct and object.
What’s the other? Stack-allocated objects are destructed when they go out of scope. Consider this code snippet:
.
{
Foo A; // A is created on the stack
{
Foo B; // B is created on the stack
// code here. This might cause an exception, but that’s ok
B.Hello(); // let’s use B
// code here...
} // B is destroyed at its scope end
} // A is destroyed at its scope end
A stack-allocated object has its storage space allocated at the point it is constructed, and it is destructed when it “goes out of scope”, that is, execution leaves the scope – the block { } – where it was created. It is not ‘deleted’, because it was not ‘new’-ed (allocated on the heap), but its destructor runs.
When an exception occurs, all stack-allocated objects are destructed as the exception is propagated upwards to its handler. That means, provided that an scope-lifetime object does not throw an exception of its own when it is destructed, that you have a guarantee the destructor will always be called – either when execution normally moves on to more code, or when an exception is thrown. Either way, in the code snippet above, both B and A will have their destructor called.
RAII
This leads to a really neat trick called Resource Acquisition Is Initialization, which uses the destruction rules to make classes that look after resources and clean them up when they are no longer needed. When it is created, it is given a resource (it acquires – takes ownership – as it is initialized) and when it is destructed, it cleans up that resource.
Consider some code that turns on a tap. You want to make sure the tap is always turned off, not matter what happens, otherwise you will be flooded. You can write a RAII object that takes a newly turned on water resource, and in its destructor turns it off:
.
class TapHandler {
private:
Tap& m_tap;
public
TapHandler(Tap& tap) : m_tap(tap) {}
~TapHandler() { m_tap.TurnOff(); }
const Tap& get() { return m_tap; }
}
It is created with a reference to a tap, and the destructor always turns the tap off. That means that the lifetime of the tap being turned on can be given to an instance of this object:
.
Tap tap(CreateTap());
{
TapHandler myTap(tap);
myTap.get().TurnOn(); // Also tap.TurnOn(), same object
throw std::exception(); // oh no!
myTap.get().TurnToCold(); // never called
myTap.get().TurnOff(); // never called
}
TurnToCold() will never be called, because an exception is thrown. But myTap’s destructor is run anyway, and the tap is always turned off. Even if an exception had not been thrown, you could rely on the tap being turned off – you never needed to remember to code it, because you used a RAII object that always did it.
If you had used a TapHandler as a member of a class, then when an instance of that class was destroyed, because all its members are destroyed too, the turned on tap would be turned off.
You can do write RAII objects for any kind of resource – Windows GDI handles, network sockets, file handles… and pointers.
Back to smart pointers
A smart pointer is an example of a RAII object. Unique_ptr only allows one owner of a pointer; shared_ptr keeps a reference count. Both of them control pointer lifetime in different ways; both mean that will well-written, modern C++, you should never write the keyword ‘delete’ – never manually manage lifetime.
One other thing: pointer access semantics. When you have a pointer, you use the arrow operator to access a member field or method:
. foo->bar();
For languages like Delphi which automatically dereference pointer access and would write the above as foo.bar() even though foo is heap-allocated, this seems unnecessary. (You can do this two ways: through the arrow operator foo->bar(), which is a synonym for dereferencing the pointer and using the dot operator: (*foo).bar(). The *foo dereferences; the brackets are required because of operator precedence. Use ->.)
A smart pointer is not heap-allocated (or shouldn’t be!) so you’d think you’d use the dot operator, but it has its own methods – in fact, you can directly access the raw pointer it holds with get(), for example:
. unique_ptr<Bar> bar(new Bar()); bar.get(); // is a Bar*
Instead, the smart pointer uses operator overloading to provide a -> operator:
. bar->Open();
Calls the Open() method on the pointer bar is managing.
So you have a pointer, and access it using pointer semantics.
Back to connecting the UI and calculator
The form should own the calculator. Managing this ownership should now be clear: we will use a unique_ptr member field in the form, so that when the form is destroyed, the pointer to the calculator will be deleted and the calculator destroyed too, all automatically. You don’t need to write any code in the destructor; deletion is automatic.
In the header for the form, add #include <memory> to be able to use the smart pointers, and in the form class declaration add:
. private: // User declarations std::unique_ptr<ICalculator> m_Calc;
And in the .cpp, change the constructor to initialize the unique_ptr with an instance of a calculator:
.
__fastcall TfrmCalculator::TfrmCalculator(TComponent* Owner) :
TForm(Owner),
m_Calc(CreateCalculator(*this))
{
}
Now, the form or UI owns a calculator, and its lifetime is managed; the calculator knows about the form / UI. There is no manual lifetime or memory management required, no delete (as you might call .Free; in other languages); it all Just Works.
When you want to access the calculator, you use pointer semantics:
. m_Calc->AddDigit(5);
Part II: Connecting the UI
Time for a break from C++ language features, cool though they are. Let’s finish the UI.
Overriding the font style
FireMonkey is a styled UI, and while it can use native controls on some platforms, it mimics the native look and feel very closely – hopefully identically – in other situations. That includes the font, where the styles for each platform specify the right platform font for button text, label text, and so forth. But for the calculator, we want to override this and use a larger font for each button and the edit box, so each button has a large caption and the calculator entry and result has large text.
To do this, select all the controls. (You can select one by clicking and then holding Shift while clicking others to multiselect, or click and drag a rectangle on the form.) The Object Inspector will show the properties that are shared by the buttons and edit, and that includes the TextSettings property. Expand it by clicking the + sign, then again on the plus next to Font, and find the Size property. Set it to 30.
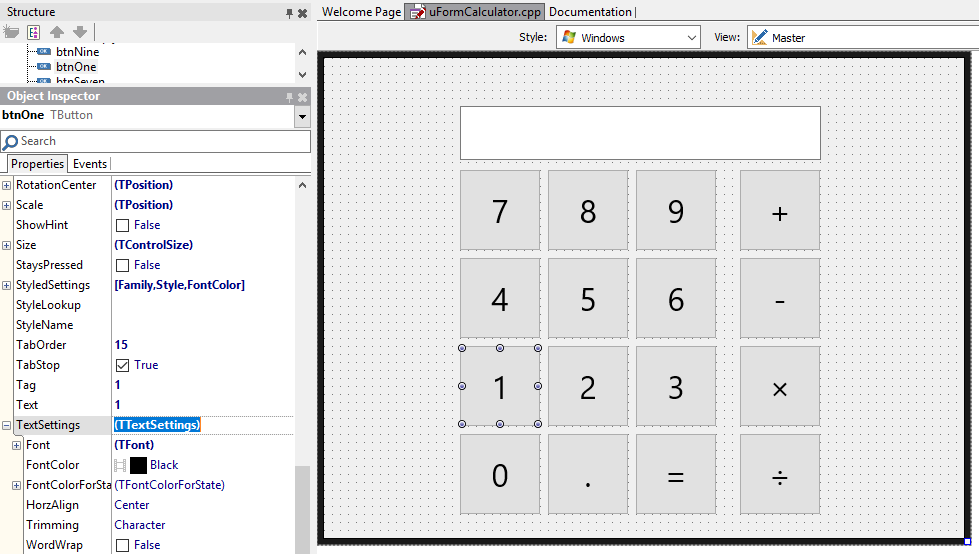
The font size changed, but what happened? Scroll up, and you’ll see the StyledSettings property has changed (it’s non-default, indicated by bold text.) Expand it, and you’ll see that the Size item is not in the set of options. The buttons and edit text are now drawing using their assigned style font, but overriding the font size set in the style. You can see the effect by clicking the checkbox next to Size on and off; it toggles between the style font size and the one you set.
Experimenting with styles
Styles are a really useful part of the FMX UI framework. Not only do they allow your applications to match the look and feel (and behaviour) of controls on any platform, and using system fonts is an example, but they also contain presets for a wide variety of difference but common alternatives. A button, for example, has many slight variations depending on how it’s used. Select just a button, and then find the StyleLookup property in the Object Inspector and click the dropdown arrow. Note how many different presets there are, such as ‘refreshtoolbutton’ for a tool button (one where the border becomes visible when you mouseover) with a Refresh icon. You can add your own, too.
However, clear the StyleLookup property since for the calculator, we want our buttons to look like standard buttons and show the Text we set as a caption.
Complete style changes
You can change a FMX app’s style completely. Drop a TStyleBook on the form from the Tool Palette, and double-click it. In the style designer tab that opens, click the Merge button, and navigate to ‘C:\Program Files (x86)\Embarcadero\Studio\19.0\Redist\styles\Fmx’. Open any style, such as ‘Blend’. Then, right-click the Style Designer tab and select close, and apply changes.
Back on the form, make sure the form’s StyleBook property is set to StyleBook1. The form will now have a completely different style.
 You can load as many styles into the stylebook as you want, through its Styles list, and change them at runtime. (The Style Designer also lets you modify styles for any element. For example, a panel is normally represented by a rectangle, but it could be a roundrect or any shape or colour you want.)
You can load as many styles into the stylebook as you want, through its Styles list, and change them at runtime. (The Style Designer also lets you modify styles for any element. For example, a panel is normally represented by a rectangle, but it could be a roundrect or any shape or colour you want.)
However, for the time being delete the style book, which will revert to the default Windows platform style.
Connecting the UI
UI events
First, let’s connect up the operators. Select the Add button, and either double-click it, or in the Object Inspector’s Events tab, double-click the blank dropdown for the OnCreate event. An event handler will be generated in the form. Fill it in like so:
.
void __fastcall TfrmCalculator::btnAddClick(TObject *Sender)
{
m_Calc->SetOperator(EOperator::eAdd);
}
Repeat this for the other operator buttons. For the Equals button, call the calculator’s Equals method, and similarly for the decimal place button.
But what about the numbers? We could have a separate event handler for each, and repeat the same code, modified for each one. But code duplication is bad style. Instead, let’s make a single event handler for all buttons. Select them all, then in the Events tab of the Object Inspector, type a name in the blank space next to OnClick – for example, type ‘btnNumberClick’, and press Enter. An event handler will be created, and all buttons will use the same handler. Fill in the code to add a digit:
. m_Calc->AddDigit(0);
Obviously we need to change this depending on which button was pressed, and the Sender parameter holds that information: it is the object associated with the method, a TObject since event handlers with this signature aren’t limited to just buttons.
You could do this via a large if statement: if Sender is btnOne, call AddDigit(1), else if Sender is btnTwo… but this is messy. We would gain very little.
FMX controls can have a data payload attached, called a tag, as a property. There are several propreties: Tag, an integer; TagFloat, a floating-point number; TagString, a string; and TagObject, a TObject pointer, allowing you to associate almost anything.
In the Object Inspector, find the Tag property for each button and set it to match the button’s number – for example, set btnZero’s Tag property to 0, btnFive’s Tag property to 5, and so on. Now the event handler needs only a single line of code:
. m_Calc->AddDigit(dynamic_cast<TButton*>(Sender)->Tag);
Dynamic cast is C++’s polymorphic type casting operator. (In Delphi, this would be ‘Sender as TButton’.) TButton is a descendant of TObject, so you can cast Sender to a TButton* and that cast will succeed if it is in fact a TButton. (It might not be.) Once it is, we can access the Tag property. (In fact, Tag is introduced a few levels up, so you could cast to TFmxObject.)
A dynamic cast will return nullptr if the cast fails, and accessing the Tag could then cause an access violation. Make sure you are certain of your types – or check. Here, we know that this event handler will only be called with a button as the Sender.
Display
The display interface has a method defined, UpdateUI, which is in the form but empty. Fill it in to make the edit box display the text:
.
void TfrmCalculator::UpdateUI(const std::wstring& strText) {
edtResult->Text = strText.c_str();
}
The edit’s Text property is String, while strText is the C++ standard wide string, but you can assign one to the other through the c_str() method returning a C-style character array pointer.
The UI is now fully hooked up to the calculator. The calculator is given digits and operators, and the form can display a string by the calculator.
Part III: Entering a number
The final part of today’s post is to allow the user to enter a number, and to display that onscreen.
You can update the UI by calling m_Display.UpdateUI(std::wstring), but scattering calls to that throughout the calculator would be bad design – one method might update it with some text, some with another. What is better is to have a single place that is responsible for updating the UI that figures out what to display based on the calculator’s current state.
Add a private void method UpdateUI() in the header and implement it in the calculator. Until we have a number, this will display nothing.
.
void TCalculator::UpdateUI() {
m_Display.UpdateUI(L"");
}
We’ll fill in that method later.
Entering a number
The calculator is told when the user presses a digit, but it needs to assemble those digits into a number. How? The first thing to realise is that accumulating digits is not a calculator’s responsibility – a calculator is really only responsible for doing calculations. Separating responsibilities, and making a class only do one thing, leads to clear, concise, and understandable code.
Given that, let’s define a new class to accumulate digits, that we can query for a number. Define this in the header:
.
class Accumulator {
private:
int m_Whole;
public:
Accumulator();
int Value() const;
void AddDigit(const int Digit);
};
This defines a class which stores an integer number, can be queried for that number, and can have a digit appended to that number.
Give the calculator a member variable:
.
class TCalculator : public ICalculator {
private:
ICalculatorDisplay& m_Display;
Accumulator m_Accum;
void UpdateUI();
And initialise it in the constructor:
.
TCalculator::TCalculator(ICalculatorDisplay& Display) :
m_Display(Display),
m_Accum()
{
}
We can now fill in the AddDigit method to defer to this object to build the number, and update the UI:
.
void TCalculator::AddDigit(const int Digit) {
m_Accum.AddDigit(Digit);
UpdateUI();
}
Finally, the UI can display whatever the accumulator has got:
.
void TCalculator::UpdateUI() {
m_Display.UpdateUI(std::to_wstring(m_Accum.Value()));
}
This uses the to_wstring method that converts an integer to a string.
Let’s fill out the accumulator class. It’s pretty simple: initialises the number it has to 0, returns that number in the Value() method, and in AddDigit, adds that digit. That part is also simple: if the accumulator has the value 1, and the user presses 2 to turn that into 12, we just multiply the current accumulated value by ten and add the digit.
.
Accumulator::Accumulator() :
m_Whole(0)
{}
int Accumulator::Value() const {
return m_Whole;
}
void Accumulator::AddDigit(const int Digit) {
m_Whole = m_Whole * 10 + Digit;
}
Things to note:
- The constructor can initialise a list of all member variables; here we just have one, m_Whole
- What does the ‘const’ mean after the method name, in ‘int Accumulator::Value() const’? It means that the method does not change the state of the object. This is useful for optimization and more.
- Why ‘whole’? Because currently we only support entering an integer, or whole, number. We really want to enter a real number, a floating point number. How are we going to do this?
If you run the app, you should now be able to type in a number and see the screen update to display it.
Handling the decimal point and introducing boost::optional
The logic for appending a digit to a integer or whole number is simple. But doing the same to the fractional side of a number is not quite so easy.
Let’s examine the basic method. Keeping the whole part a separate number, we can track the fractional part as another integer, and append the digit the same way. We can convert the integer to a fraction (123 to 0.123) later. To do this, we split the append-digit logic away to another method, and call it on either the whole or fractional member variable depending on if the decimal point has been pressed. How do we track that? Keep state; add a boolean member and when the decimal point is pressed, pass that from the calculator to the accumulator.
However, how do we keep track of leading zeroes? How do we tell the difference between 0 as no value, and 0 as something to keep and transform to ‘01’? How do we represent that in an integer, anyway? You can’t. Assuming we keep the fractional value as a number, we need to track the number of leading zeroes separately. This is rapidly becoming messy. It’s not going to be as simple as the integer whole number was, but we can simplify it.
First, let’s expand to keep track of the whole and fractional parts separately; to store if the user has pressed the ‘.’ button or not (if they are entering the fractional part); and add a digit to the appropriate half.
Extend the header to add a int m_Frac value; change Value() to return a double (a 64-bit floating-point type), add a method SetEnteringFraction to flag that the user is now typing into the fractional side, and change AddDigit to use it. We’ll also, for reasons we’ll get to later, change Value() to get the value of the whole and fractional parts through a getter method for each. Right now they will just return the member variable, but these will change soon. You should end up with something like this (only the implementation shown):
.
Accumulator::Accumulator() :
m_Whole(0),
m_Frac(0),
m_EnteringFraction(false)
{
}
double Accumulator::Value() const {
return Whole() + Frac();
}
double Accumulator::Whole() const {
return m_Whole;
}
double Accumulator::Frac() const {
// Todo: fill in logic here
}
void Accumulator::SetEnteringFraction() {
m_EnteringFraction = true;
}
int Accumulator::InternalAddDigit(const int& Value, const int Digit) {
return Value * 10 + Digit;
}
void Accumulator::AddDigit(const int Digit) {
if (m_EnteringFraction) {
m_Frac = InternalAddDigit(m_Frac, Digit);
} else {
m_Whole = InternalAddDigit(m_Whole, Digit);
}
}
The secret to the fractional value, ie turning 123 into 0.123, lies in calculating its magnitude (tens, hundreds, etc) and dividing it by that amount, which is ten to the nth power. log10(123) will give 2, whereas we want 3, to divide by 10^3 = 1000, because 123 / 1000 = 0.123.
Thus, the method looks like:
.
double Accumulator::Frac() const {
if (m_Frac != 0) {
return m_Frac / pow(10, floor(log10(m_Frac) + 1));
}
return 0.0;
}
This is the most complicated part of the whole blog series 🙂
This avoids doing the logarithm with a value of 0, or dividing 0 by a value, returning 0 in this situation as a fallthrough.
Now you can enter a complete, decimal-point-separated number by digits individually. But we still haven’t addressed how to handle leading zeroes. Let’s keep a count of them (we’ll address when to know a 0 is a leading zero in a moment), so the above line becomes:
. return m_Frac / pow(10, floor(log10(m_Frac)) + m_FracLeadingZeroes + 1);
(Make sure you initialise the count of leading zeroes to 0 in the constructor.)
But how do we tell the difference between m_Frac being ‘not entered’, so 0 is a leading 0, and for legitimately holding a value? Because we track leading zeroes, we can assume if m_Frac is not equal to 0, it’s a valid value. But this logic is obscure – someone reading the code later might wonder what’s going on.
Optionals
What if there was a way to track if a variable genuinely held a value, or was empty?
In C# or Delphi, this is called a ‘nullable type.’ In C++, we use a boost template called ‘optional’. An optional may, or may not, have a value, and you can check if it does. And while you could implement the accumulator without using them, using them makes the state clear and provides a very nice demonstration – important because we’re going to use them in a much more essential place next blog post.
Hopefully you installed boost at the beginning of this post; it takes a while. The Boost library has a vast variety of useful classes and methods; optional is just one.
An optional is declared like so:
. boost::optional<int> m_Frac;
and has the following features:
- Can be constructed with or without a value: m_Frac() does not have a value; m_Frac(0) has a value of 0
- Can be reset to not hold anything: m_Frac.reset();
- Can be checked if it has a value in an if statement, as a bool: if (m_Frac) { … } is true and goes into the building of the if only when the optional holds a value; if (!_Frac) { … } will enter the loop if the optional does not have a value.
- Can get the value it holds – if it has one – through pointer semantics, specifically being dereferenced: int i = *mFrac;
Does this look familiar? It’s very similar to a smart pointer, and a smart pointer, although we introduced it as a way of controlling lifetime, is also conceptually something that may have a value (a pointer) or may not (nullptr).
Include <boost/optional/optional.hpp>, and change m_Frac to boost::optional<int> m_Frac; The constructor should also be changed to initialise it as ‘m_Frac()’, ie without a value, because the accumulator starts off without the fractional part having a value.
AddDigit() can now check if it’s counting leading fractional zeroes like so:
.
if (Digit == 0 && !m_Frac) {
++m_FracLeadingZeros;
} else { ...
If the fractional part has no value, and the user entered 0, it must be a leading zero. The else statement will add the digit as normal.
"++" here increments the value by 1. ++i is a preincrement, and i++ is a postincrement; the difference lies in evaluating. If i has the value 1, j = ++i gives j a value of 2, and i of 2 (i is incremented first, ‘preincrement’); but j = i++ gives j a value of 1 and i a value of 2 (i is incremented second, ‘postincrement’). Pre- and pos- refers to evaluation. How often do you need this? Most often in loops, but modern C++ rarely loops via integers. It’s a holdover from C. The above code could be written either way.
The Frac() method can check if there is a fractional value and return 0.0 if not, and should get the value by *m_Frac. Finally, since we want to avoid duplicating code, the AddDigit method now has to add a digit to either an int or a boost::optional<int>; change the whole number to an optional too, because it is valid for it not to have a value yet. It's very valid for it not to have a value: the user might go straight to entering the fraction, and while 0 is a valid value in this case, this code is meant to demonstrate optional<>. Remember to initalise it to empty, and to check if it has a value when returning its value in Whole().
Putting it all together, we get the following accumulator class:
.
Accumulator::Accumulator() :
m_Whole(),
m_Frac(),
m_FracLeadingZeros(0),
m_EnteringFraction(false)
{
}
double Accumulator::Value() const {
return Whole() + Frac();
}
double Accumulator::Whole() const {
if (m_Whole) {
return *m_Whole;
}
return 0.0;
}
double Accumulator::Frac() const {
// Convert an integer like 123 to 0.123
// Magnitude can be calculated via log10
// log10(123) -> 2, +1 -> 3
// pow(10, 3) -> 1000
// 123 / 100 = 0.123
// Note leading zeroes - handle separately
if (m_Frac && (*m_Frac != 0)) {
return *m_Frac / pow(10, floor(log10(*m_Frac) + m_FracLeadingZeros + 1));
}
return 0.0;
}
void Accumulator::SetEnteringFraction() {
m_EnteringFraction = true;
}
int Accumulator::InternalAddDigit(const boost::optional<int>& Value, const int Digit) {
// Add a digit to the number. If it doesn't exist, the number is the digit
if (Value) {
return *Value * 10 + Digit;
} else {
return Digit;
}
}
void Accumulator::AddDigit(const int Digit) {
if (m_EnteringFraction) {
// Leading zeroes won't get added, mathematically (to enter 1.00001, for
// example, InternalAddDigit will multiply by 10 and add 0.) Track separately
if (Digit == 0 && !m_Frac) {
++m_FracLeadingZeros;
} else {
m_Frac = InternalAddDigit(m_Frac, Digit);
}
} else {
m_Whole = InternalAddDigit(m_Whole, Digit);
}
}
You can now enter a decimal fractional number. Is using optional<> overkill here? Possibly, because it could be implemented another way, but it is clear – you can see when a variable may or may not have a value. The bit I don’t like is the logic to count the leading zeroes in AddDigit – the if statements are too nested and starting to become unclear. That logic could mostly be moved to InternalAddDigit, but the leading zero count should only occur if we’re dealing with the fractional part. It works, but it is not as simple as I would like. Suggestions are welcome.
Overview
What have we covered this week? A lot:
- C++:
- Ownership: being clear what owns and is responsible for freeing what resources
- RAII: Resource Acquisition Is Initialisation, a key C++ technique
- Smart pointers, memory management using RAII
- That modern C++ never uses the delete keyword: never manually manage memory
- FireMonkey:
- Styles
- Overriding style elements
- Importing completely new styles
- Connecting event handlers and attached data to controls
- C++ again:
- The Boost library
- boost::optional<>, one of many useful classes, and the concept of an optional or nullable type and (perhaps over-)use of it
- Some math (the most complicated bit of this whole blog series!)
- Putting it all together, a class that accumulates key presses to have optional whole and fractional parts of a number, returning the whole thing as a floating-point number
Next time, we examine operators (implementing addition, subtraction etc with small classes), moving a number from the accumulator to a left or right operand, and putting it all together – including a more accurate or important use of optionals – into a functioning calculator.
Read more
Next in the Learn to program C++ with C++Builder series:
- Part 1: Introduction and Installation
- Part 2: Building and Debugging
- Part 3: Design, Architecture, and UIs
- Part 4: Real Code and Useful C++: Ownership, smart pointers, styles, and optional values
- Part 5: Operators, and Final Application!

