






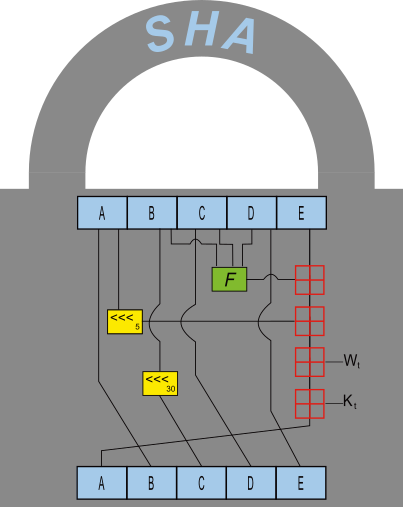
 I've always been fascinated by encryption & compression, but my favorite is probably the cryptographic hash function. A hash function is a one-way algorithm that takes an input of any size and always produces the same size output. It is one-way in that there is information loss — you can't easily go from the output to the input again. The cryptographic hash is a more secure version of the hash function. It is most often used in signing to validate that data hasn't been modified.
I've always been fascinated by encryption & compression, but my favorite is probably the cryptographic hash function. A hash function is a one-way algorithm that takes an input of any size and always produces the same size output. It is one-way in that there is information loss — you can't easily go from the output to the input again. The cryptographic hash is a more secure version of the hash function. It is most often used in signing to validate that data hasn't been modified.
Per Wikipedia, the ideal cryptographic hash function has five main properties:
- it is deterministic so the same message always results in the same hash
- it is quick to compute the hash value for any given message
- it is infeasible to generate a message from its hash value except by trying all possible messages
- a small change to a message should change the hash value so extensively that the new hash value appears uncorrelated with the old hash value
- it is infeasible to find two different messages with the same hash value
SHA Family Icon by Uwe Martens – Used under CC BY-SA 4.0
The Message Digest family of cryptographic hashes used to be the main players in the area, but they were found to be insecure. Now SHA family rules as the main workhorse of modern cryptography.
The basis of hash support first appeared in the RTL around the 2009 release but in XE8 (2015) we got the System.Hash unit, which brought the MD5, SHA-1, and Bob Jenkins hashes. Then in 10.0 Seattle (2015) it was expanded with SHA-2 support. Most recently in 10.2 Tokyo (2017) the hash functions were expanded to accept either a string or stream in addition to the original bytes input.
The SHA Family includes SHA-0, SHA-1, SHA-2, & SHA-3 family of hashes. SHA-0 is obsolete, and SHA-3 is an improvement on SHA-2. In practice I see most hashes using either SHA-1 or SHA-2. SHA-1 always produces a 160-bit (20-byte) hash (digest), while SHA-2 includes 224, 256, 384, and 512-bit outputs, making it both more secure and more flexible. SHA 256 & 512 represent 32 and 64-bit word size hash algorithms. The 224, 256, & 384 size digests are truncated versions of the 256 & 512 algorithms.
So how do you use it in C++Builder and Delphi? I'm glad you asked. Once you have included the System.Hash unit then you can use the methods of the THashSHA2 class to create the digest. I'll show you how to use GetHashString, but know there are other variations you can use too. The GetHashString takes either a string or a stream and returns a hexadecimal string of the hash.
In C++Builder your code would look like:
Edit512->Text = THashSHA2::GetHashString(
EditMessage->Text,
THashSHA2::TSHA2Version::SHA512);
and in Delphi your code would look like:
Edit512.Text := THashSHA2.GetHashString(
EditMessage.Text,
THashSHA2.TSHA2Version.SHA512).ToUpper;
I made a little sample app that generates all the different hashes from the text you provide. It is a FireMonkey app, so will work on all the platforms, but the hash code will work in any type of app. There are both C++ and Delphi versions included.
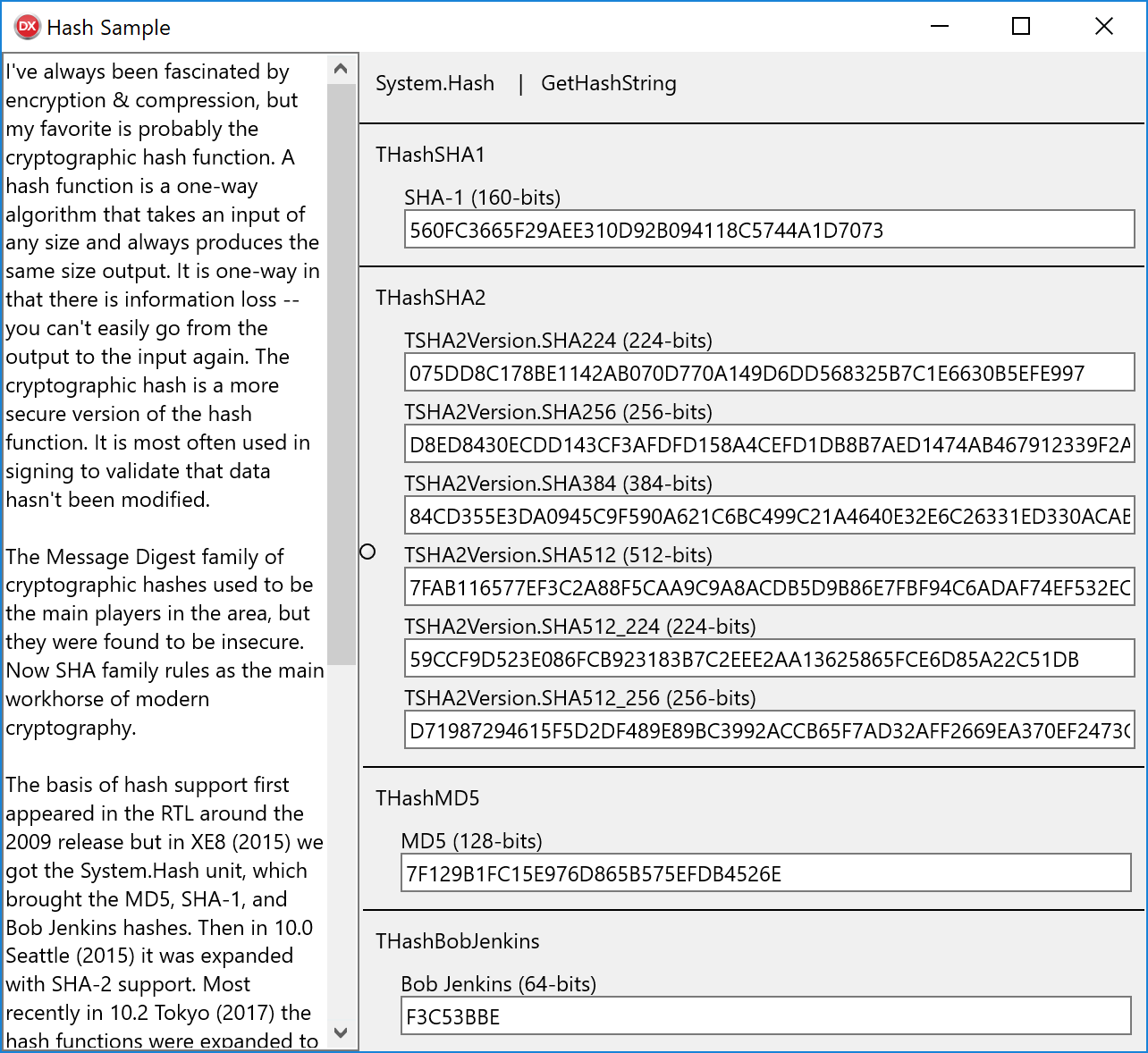
[ShaHashSample.7z – Delphi & C++Builder 10.2.3 Tokyo – 401 KB ]