You know those tweets that you see once but can never find again? I remember seeing one a while ago where someone tweeted to #sqlhelp asking if the internal inserted and deleted tables had statistics or if they were like table variables, which didn’t.
This is a great question in general. But then it got me thinking – how do you prove this? I wanted to know the answer as well so I decided to look into this. And I went down the wrong sort of rabbit hole trying to figure this out. Eventually I talked to a friend about this and got pointed in the right direction…
And the answer to how you find which statistics are used is…?
Once upon a time, you used Trace Flags. Paul White wrote a great post about this. But if you look at the note, you see that it only applies to cardinality estimator set to 70, which means SQL Server 2012 or lower.
But then I stumbled on this blog post from Pedro Lopes and everything is now a whole lot easier: If you are on SQL Server 2016 SP2 or higher, it’s part of the execution plan. I'm not 100% sure what this means for SQL Server 2014. I don't know if the Trace Flags work on that version or if it's a subtle hint to upgrade. 🙂 That may require extra investigation.
Time to Test:
Let’s see what happens when you select from a regular table, the inserted/deleted tables, and from a table variable.
The original question was just about table variables and the inserted and deleted tables. But I want to start with a regular table because we know they have statistics for the Query Optimizer to use. First, I ran the following statement:
SELECT * FROM Person as p WHERE Last_Name = 'Melkin'
When I look at the properties of the first node, I see the properties for OptimizerStatUsage:
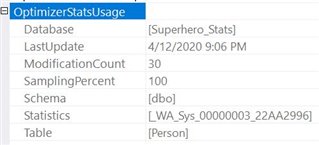
We can see that it's using auto-created statistics on the column. What happens when I create an index on the Last_Name field?
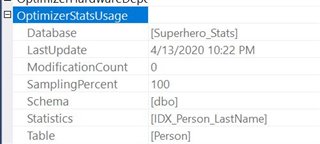
We can see that the new index's statistics are being used.
Inserted\Deleted Tables
Now, let's see what happens when we select from the inserted and deleted tables. I decided to use a simple trigger for this test so I could isolate the results.
CREATE OR ALTER TRIGGER Person_itr ON dbo.Person FOR INSERT AS BEGIN SELECT * FROM inserted as i JOIN Person as p on i.Person_ID = p.Person_ID END GO
I ran a simple INSERT statement. When I looked at the execution plan properties for the SELECT statement inside the trigger, I see this:
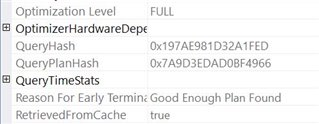
Note that there is no OptimizerStatUsage. There are no statistics involved in this statement.
I modified the trigger to include one regular table to see what happens:
CREATE OR ALTER TRIGGER Person_itr ON dbo.Person FOR INSERT AS BEGIN SELECT * FROM inserted as i JOIN Person as p on i.Person_ID = p.Person_ID END GO
I ran an INSERT and looked at the execution plan and still no OptimizerStatUsage:
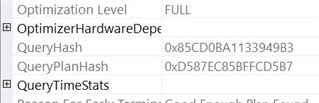
I found this interesting because Person.Person_ID is the clustered primary key on that table and it is being used in the execution plan:
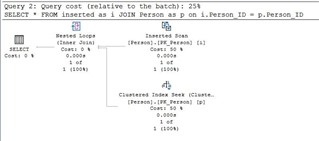
So what happens when I add another table to the trigger?
CREATE OR ALTER TRIGGER Person_itr ON dbo.Person FOR INSERT AS BEGIN SELECT * FROM inserted as i JOIN Person as p on i.Person_ID = p.Person_ID JOIN Alter_Ego_Person as aep ON p.Person_ID = aep.Person_ID END GO
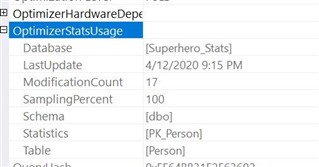
While there are two regular tables being used, only one of them had a statistic involved.
Table Variables
So now let's take a look at table variables. For this next test, I wanted to look at a table variable with a clustered primary key and one without anything. Because after all, a primary key constraint is an index, which has statistics. But our question is not whether there are statistics but are they being used?
NOTE: Because table variables only last the length of the session, I ran all of the test statements together at once. I'm breaking up the relevant statements here for demonstration purposes.
My test variables are fairly simple:
DECLARE @Person_noPK TABLE (First_Name varchar(30), Last_Name varchar(30)) DECLARE @Person_PK TABLE (First_Name varchar(30), Last_Name varchar(30) PRIMARY KEY CLUSTERED)
My first test was to just SELECT from each of the table variables:
SELECT * FROM @Person_noPK WHERE Last_Name = 'Melkin' SELECT * FROM @Person_PK WHERE Last_Name = 'Melkin'
Here's the results for the table variable with no primary key:
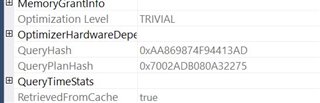
And now for the one with a Primary Key:
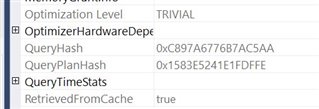
Neither one used a statistic as part of the execution plan.
Now what happens if you join to a table?
SELECT * FROM Person as p LEFT JOIN @Person_noPK as tv ON p.Last_Name = tv.Last_Name SELECT * FROM Person as p LEFT JOIN @Person_PK as tv ON p.Last_Name = tv.Last_Name
The results for the table variable with no primary key:
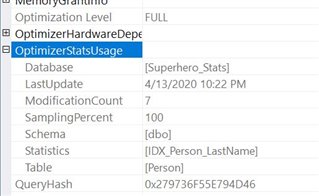
Notice that the statistic being used is for the Person table. Now what happens when you use the table variable with a primary key? 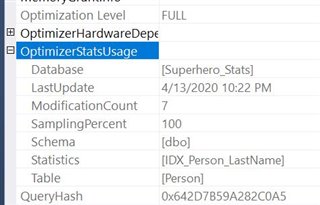
Same results – just the regular table's index is used.
So what happens if we switch the query?
SELECT * FROM @Person_noPK as p LEFT JOIN Person as tv ON p.Last_Name = tv.Last_Name SELECT * FROM @Person_PK as p LEFT JOIN Person as tv ON p.Last_Name = tv.Last_Name
First, the results for the table variable without the primary key:
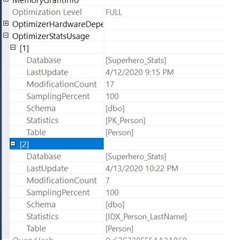
The cool thing is we now see 2 statistics are involved with that query. However, both are on the Person table. So what does that mean for the table variable with a primary key?
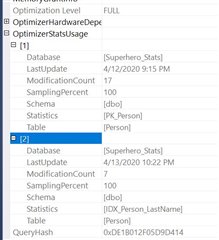
It doesn't make a difference. Even though there is technically a statistic for that table variable since it does have a primary key constraint, it's not being used in the query.
What did we learn?
I think it's safe to say that the inserted and deleted tables and table variables do not have statistics that are used by the Query Optimizer when used in queries.
We've also learned how to tell which statistics are being used in our queries. When we're troubleshooting query performance, knowing this information may make it easier to figure out what we need to know in order to understand what we can do for faster performance.
But knowing where to look is the first step….